Podatek abstrakcji: koszt kontenera, którego nie potrzebujesz
Gdy zespół sięga po Dockera wyłącznie po to, żeby nałożyć limit CPU i pamięci na jeden proces — pipeline danych, demona monitoringu, schedulowanego joba — płaci podatek abstrakcji. cgroups v2 (Control Groups w wersji 2) dostarcza ten sam prymityw izolacji natywnie z kernela, bez daemonów, bez warstw obrazów, bez ceremonii OCI. Container runtime (containerd, runc) musi zainicjalizować środowisko z namespacem, zamontować OverlayFS i skonfigurować wirtualną sieć — nawet jeśli jedynym celem jest throttling jednego wątku.Zunifikowane w kernelu 4.5 i domyślnie aktywne na Arch Linux od kernela 5.8+, cgroups v2 eliminuje cały ten narzut operacyjny dla scenariuszy resource governance pojedynczego procesu.Ten artykuł rozkłada architekturę zunifikowanej hierarchii cgroups v2, jej integrację z modelem transient units w systemd oraz programatyczne sterowanie przez Python — dając pełną izolację zasobów bez narzutu stosu kontenerowego.cgroups v2: Fundamentalna zmiana architektury względem v1
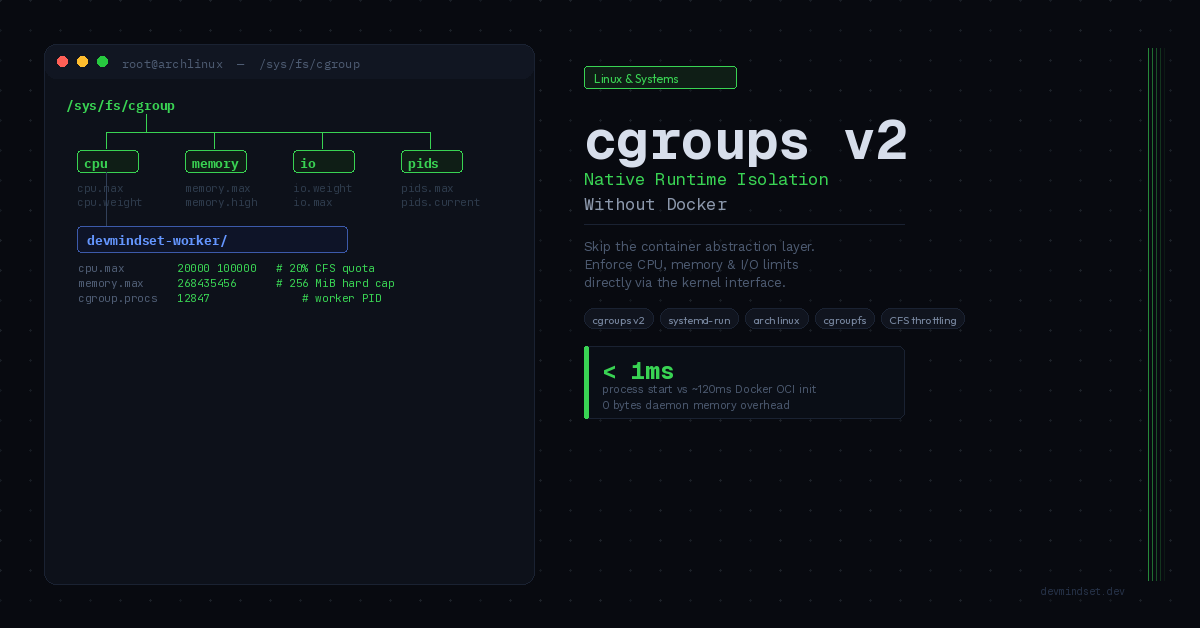
Krytycznym błędem cgroups v1 była fragmentaryczna hierarchia per-kontroler. Limity CPU żyły w/sys/fs/cgroup/cpu/, limity pamięci w /sys/fs/cgroup/memory/ — niezależne drzewa zdolne do generowania konfliktujących przypisań zasobów i operacyjnie niestabilne przy atomowej migracji procesów między kontrolerami.cgroups v2 narzuca jedną, zunifikowaną hierarchię zakorzenioną w /sys/fs/cgroup/. Wszystkie kontrolery — cpu, memory, io, pids — działają w jednym spójnym drzewie. Kluczowy niezmiennik architektoniczny: proces może należeć dokładnie do jednej cgrupy.Weryfikacja zunifikowanej hierarchii
# Weryfikacja aktywnego trybu cgroups v2
$ mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
# Inspekcja dostępnych kontrolerów
$ cat /sys/fs/cgroup/cgroup.controllers
cpuset cpu io memory hugetlb pids rdma misccgroup2 jako typ FS i zunifikowany zestaw kontrolerów — system jest w pełni zmigrowany. Na systemach hybrydowych parametr kernela cgroup_no_v1=all wymusza tryb wyłącznie v2.Bezpośrednie zarządzanie cyklem życia cgrupy
Zarządzanie cgroupami sprowadza się do manipulacji systemem plików. Tworzenie cgrupy = tworzenie katalogu. Przypisanie procesu = zapis PID docgroup.procs. Ograniczanie zasobów = zapis wartości do plików interfejsu kontrolera.Tworzenie i konfiguracja cgrupy
# Tworzenie cgrupy dla izolowanego workloadu
$ mkdir /sys/fs/cgroup/devmindset-worker
# Włączenie kontrolerów CPU i pamięci dla tej podgałęzi
$ echo "+cpu +memory" > /sys/fs/cgroup/devmindset-worker/cgroup.subtree_control
# Cap CPU: 20% jednego rdzenia (quota/period w mikrosekundach)
$ echo "20000 100000" > /sys/fs/cgroup/devmindset-worker/cpu.max
# Twardy limit pamięci: 256 MiB
$ echo $((256 * 1024 * 1024)) > /sys/fs/cgroup/devmindset-worker/memory.max
# Przypisanie bieżącego procesu shella do cgrupy
$ echo $$ > /sys/fs/cgroup/devmindset-worker/cgroup.procscpu.max przyjmuje pary $QUOTA $PERIOD, bezpośrednio mapując na throttling pasma CFS (Completely Fair Scheduler). Każdy proces przekraczający 20ms w oknie 100ms zostanie ograniczony na poziomie schedulera — bez żadnego daemona w userspace.Integracja z systemd: Transient units jako prymityw izolacji
W produkcyjnych środowiskach na systemach z systemd,systemd-run jest idiomatyczną abstrakcją nad cgroups v2. Uruchamia proces wewnątrz transient scope lub unit serwisowego, dziedzicząc model delegacji cgroup z systemd.# Uruchomienie izolowanego procesu z ograniczeniami zasobów
$ systemd-run
--scope
--unit=devmindset-worker
--property=CPUQuota=20%
--property=MemoryMax=256M
--property=IOWeight=10
/usr/bin/python3 /opt/workers/pipeline_runner.py
# Live resource accounting
$ systemctl status devmindset-worker.scope
$ cat /sys/fs/cgroup/system.slice/devmindset-worker.scope/cpu.stat--scope tworzy transient unit ograniczony do bieżącej sesji, --service tworzy pełny serwis z zarządzaniem cyklem życia przez systemd. IOWeight mapuje na wagę schedulera I/O CFQ/BFQ, realizując proporcjonalną alokację przepustowości I/O.Programatyczne sterowanie przez Python
Dla dynamicznego zarządzania workloadami — uruchamiania izolowanych workerów w runtime, regulacji quotów na podstawie telemetrii, implementacji mechanizmów backpressure — Python zpathlib dostarcza czysty, idiomatyczny dostęp do interfejsu cgroupfs bez zewnętrznych zależności.from __future__ import annotations
import os
import subprocess
from pathlib import Path
from typing import Final
# Micro-Rationale: pathlib.Path zamiast konkatenacji stringów —
# bezpieczna typowo manipulacja FS, O(1) budowanie ścieżek, zero zewnętrznych deps.
CGROUP_ROOT: Final[Path] = Path("/sys/fs/cgroup")
class CgroupV2Controller:
"""Zarządza pojedynczą hierarchią cgroups v2 dla izolacji procesów.
Wymusza quota CPU i twardy limit pamięci na nazwanej cgroup.
Implementuje protokół context managera dla deterministycznego sprzątania.
"""
def __init__(
self,
name: str,
cpu_quota_percent: int = 25,
memory_max_mib: int = 256,
) -> None:
if not 1 <= cpu_quota_percent <= 100:
raise ValueError(f"cpu_quota_percent musi być w [1, 100], otrzymano {cpu_quota_percent}")
if memory_max_mib < 16:
raise ValueError(f"memory_max_mib musi być >= 16 MiB, otrzymano {memory_max_mib}")
self.name = name
self._cpu_quota_percent = cpu_quota_percent
self._memory_max_bytes = memory_max_mib * 1024 * 1024
self._cgroup_path = CGROUP_ROOT / name
def _write(self, interface: str, value: str) -> None:
"""Zapisuje wartość do pliku interfejsu cgroup.
Args:
interface: Nazwa pliku interfejsu cgroup (np. 'cpu.max').
value: Wartość do zapisania.
Raises:
PermissionError: Brak CAP_SYS_ADMIN.
OSError: Interfejs cgroup niedostępny.
"""
target = self._cgroup_path / interface
try:
target.write_text(value, encoding="utf-8")
except PermissionError as exc:
raise PermissionError(
f"Brak uprawnień do zapisu w {target}. "
"Uruchom jako root lub z CAP_SYS_ADMIN."
) from exc
except OSError as exc:
raise OSError(f"Błąd zapisu '{value}' do {target}: {exc}") from exc
def create(self) -> "CgroupV2Controller":
"""Tworzy katalog cgrupy i konfiguruje limity zasobów.
Returns:
Self — dla fluent chaining.
Raises:
FileExistsError: Cgroup o tej nazwie już istnieje.
"""
try:
self._cgroup_path.mkdir(parents=False, exist_ok=False)
except FileExistsError:
raise FileExistsError(f"Cgroup '{self.name}' już istnieje w {self._cgroup_path}")
self._write("cgroup.subtree_control", "+cpu +memory")
# Quota CPU: $QUOTA $PERIOD w mikrosekundach (CFS bandwidth throttling)
period_us = 100_000
quota_us = int(period_us * self._cpu_quota_percent / 100)
self._write("cpu.max", f"{quota_us} {period_us}")
# Twardy limit pamięci — OOM killer odpala przy przekroczeniu
self._write("memory.max", str(self._memory_max_bytes))
return self
def assign_pid(self, pid: int) -> None:
"""Przenosi proces do tej cgrupy przez zapis do cgroup.procs.
Args:
pid: PID procesu docelowego.
Raises:
ProcessLookupError: Proces o podanym PID nie istnieje.
"""
try:
os.kill(pid, 0) # Sonda: rzuca wyjątek jeśli PID nieważny
except ProcessLookupError:
raise ProcessLookupError(f"Nie znaleziono procesu o PID {pid}.")
self._write("cgroup.procs", str(pid))
def assign_current_process(self) -> None:
"""Przenosi wywołujący proces do tej cgrupy."""
self.assign_pid(os.getpid())
def destroy(self) -> None:
"""Usuwa katalog cgrupy. Wszystkie procesy muszą być wcześniej zmigrowane.
Raises:
OSError: Cgroup nadal zawiera procesy.
"""
procs = (self._cgroup_path / "cgroup.procs").read_text().strip()
if procs:
raise OSError(
f"Nie można usunąć cgroup '{self.name}': "
f"aktywne PIDs: {procs.splitlines()}"
)
self._cgroup_path.rmdir()
def __enter__(self) -> "CgroupV2Controller":
return self.create()
def __exit__(self, *_: object) -> None:
try:
self.destroy()
except OSError:
pass # Best-effort cleanup; logować w produkcji
# --- Przykład użycia ---
if __name__ == "__main__":
worker_proc = subprocess.Popen(["/usr/bin/python3", "/opt/workers/cpu_intensive_task.py"])
with CgroupV2Controller(
name="devmindset-worker",
cpu_quota_percent=20,
memory_max_mib=256,
) as cgroup:
cgroup.assign_pid(worker_proc.pid)
worker_proc.wait()Porównanie narzutu: Docker vs. bezpośrednie cgroups v2
| Wymiar | Docker (runc) | Bezpośrednie cgroups v2 |
|---|---|---|
| Daemon runtime | containerd + dockerd | Brak |
| Latencja startu procesu | ~80–150ms (OCI init) | < 1ms (mkdir + write) |
| Izolacja systemu plików | Wymagany mount OverlayFS | Nie dotyczy |
| Namespace sieciowy | Wirtualna karta sieciowa + iptables | Nie dotyczy |
| Narzut pamięci | ~15–30 MiB per kontener | Zero |
| Interfejs kernela | Pośredni (runc → seccomp → cgroup) | Bezpośredni |
| Przypadek użycia | Pełna izolacja aplikacji, przenośność | Resource governance jednego procesu |
Podsumowanie: Dobór właściwego prymitywu izolacji
cgroups v2 nie jest alternatywą dla Dockera — to mechanizm, na którym Docker jest zbudowany. Sięgnięcie po cgroups v2 bezpośrednio oznacza operowanie na właściwym poziomie abstrakcji dla danego problemu. Na zahartowanym systemie Arch Linux z zestawem długo działających workerów, background scraperów lub demonów inferencji ML, 150-liniowy kontroler Python i trzy flagisystemd-run dostarczają pełną izolację runtime bez operacyjnego narzutu stosu orkiestracji kontenerów.Inżynierowie rozumiejący prymitywy kernela, na których zbudowane są ich narzędzia, zawsze będą debugować szybciej, profilować dokładniej i projektować architektury bardziej efektywnie niż ci, którzy operują wyłącznie przez warstwy abstrakcji.Skoro schodzimy do prymitywów kernela bez warstwy Dockera, ten sam poziom abstrakcji — syscalle i kolejki współdzielone z jądrem — rozbiera tekst o tym, kiedy epoll przestaje wystarczać wobec io_uring. Czym jest proces, który tymi cgroupami izolujesz, pokazuje z kolei materiał o tym, co fork() naprawdę robi pod spodem.