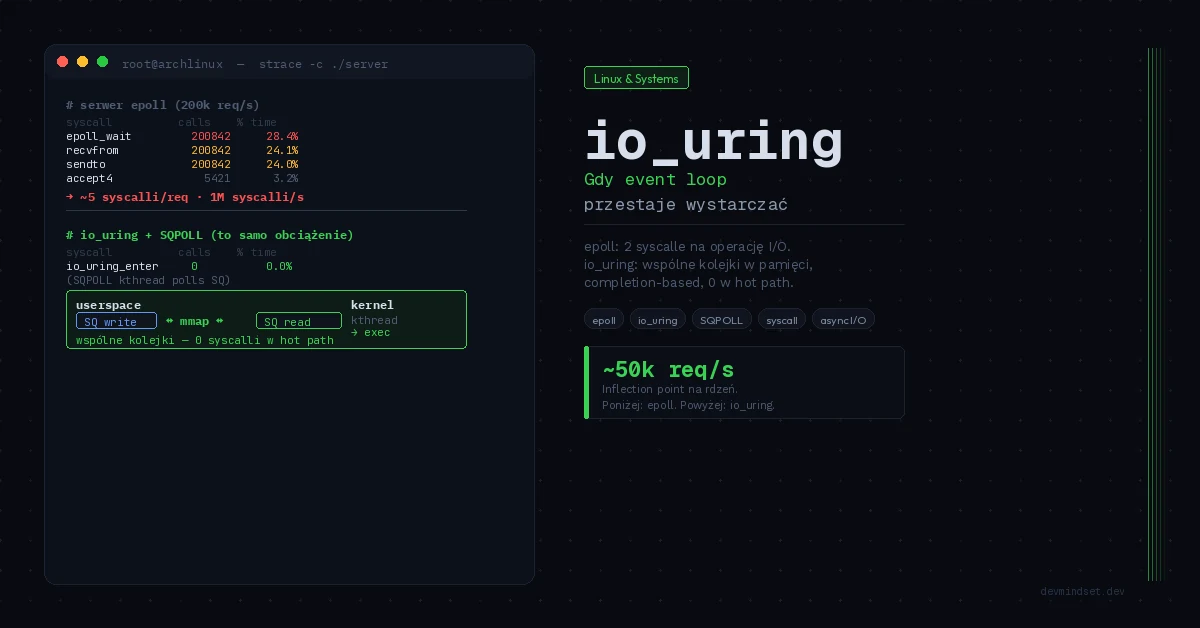
Problem skalowania I/O w userspace
Gdy aplikacja sieciowa obsługuje 10 tysięcy połączeń, model „jeden wątek per połączenie” rozsypuje się o ścianę kosztu kontekstu. Klasyczna odpowiedź to event loop oparty na epoll — i przez ostatnie dwie dekady ten paradygmat napędzał właściwie cały nowoczesny stos: nginx, Node.js, asyncio, tokio. Wszystko, co naprawdę szybko obsługuje połączenia w Linuksie.
Potem przyszedł 2019 i kernel 5.1, a Jens Axboe (autor BFQ I/O schedulera) wprowadził io_uring — fundamentalnie inny model asynchronicznego I/O, oparty nie na readiness notification, ale na completion notification, z dwiema współdzielonymi kolejkami między userspace a kernelem.
Ten artykuł rozkłada epoll vs io_uring na konkretne syscalle, pokazuje kiedy completion-based model faktycznie wygrywa benchmark, a kiedy to over-engineering dla workloadu, który epoll obsłuży na jednym rdzeniu z 30% headroom.
epoll — model oparty na gotowości (readiness-based)
Wprowadzony w kernelu 2.5.45 jako odpowiedź na ograniczenia select() i poll(), epoll to rejestr deskryptorów plików, dla których kernel powiadamia userspace, gdy są gotowe do operacji. Trzy syscalle definiują interfejs:
epoll_create1()— tworzy instancję epoll i zwraca jej fdepoll_ctl()— dodaje/usuwa/modyfikuje obserwowane fdepoll_wait()— blokuje (lub timeoutuje) aż któreś z fd staną się gotowe
Krytyczna pułapka: epoll powiadamia, ale nie wykonuje
Sednem modelu readiness-based jest to, że epoll_wait() mówi „socket X jest gotowy do czytania” — ale danych nie odczytuje. Userspace musi wykonać kolejny syscall read()/recv(). Każda operacja I/O to minimum dwa syscalle: jeden żeby się dowiedzieć że można, drugi żeby faktycznie wykonać.
import select
import socket
epoll = select.epoll()
server = socket.socket()
server.setblocking(False)
server.bind(("0.0.0.0", 8080))
server.listen(128)
epoll.register(server.fileno(), select.EPOLLIN | select.EPOLLET) # Edge-Triggered
connections: dict[int, socket.socket] = {}
while True:
events = epoll.poll(timeout=-1) # syscall #1: epoll_wait()
for fd, event in events:
if fd == server.fileno():
client, _ = server.accept() # syscall: accept4()
client.setblocking(False)
epoll.register(client.fileno(), select.EPOLLIN | select.EPOLLET)
connections[client.fileno()] = client
elif event & select.EPOLLIN:
sock = connections[fd]
try:
while data := sock.recv(4096): # syscall #2: recvfrom() — niezbędny!
sock.send(data) # syscall #3: sendto()
except BlockingIOError:
pass # Wszystko odczytane, czekamy na kolejne EPOLLINDla typowego cyklu accept → read → write → close mamy 4–6 syscalli per request. Każdy syscall to context switch userspace → kernel kosztujący ~100–500 ns na nowoczesnym CPU (więcej na maszynach z włączonymi mitygacjami Spectre/Meltdown). Przy 200k req/s × 5 syscalli = 1 milion syscalli na sekundę — i tu zaczyna się tarcie.
Edge-Triggered vs Level-Triggered
To rozróżnienie, które kompromituje juniorów na rozmowach. Level-Triggered (LT) — domyślny tryb — powiadamia za każdym razem, gdy fd jest gotowy. Edge-Triggered (ET) powiadamia tylko raz, gdy następuje zmiana stanu (z niegotowego na gotowy). ET wymusza dyscyplinę: w odpowiedzi na powiadomienie musisz wyczytać wszystko z bufora, bo drugiego ostrzeżenia nie będzie. Wymaga to O_NONBLOCK + pętli recv() aż do EAGAIN. ET ma mniejszy narzut (mniej spurious wakeups), ale błędna implementacja prowadzi do permanentnego stallu połączenia.
io_uring — model oparty na ukończeniu (completion-based)
io_uring nie pyta kernela „czy mogę?”. io_uring mówi kernelowi „zrób X, daj znać jak skończysz”. Mechanika opiera się na dwóch współdzielonych pierścieniowych kolejkach w pamięci, mapowanych między userspace a kernel space przez mmap():
- Submission Queue (SQ) — userspace zapisuje operacje (SQE — Submission Queue Entry)
- Completion Queue (CQ) — kernel zapisuje wyniki (CQE — Completion Queue Entry)
Synchronizacja przebiega przez memory barriers (atomowe operacje na head/tail wskaźnikach), nie przez syscalle. Trzy syscalle stanowią cały interfejs: io_uring_setup(), io_uring_enter(), io_uring_register(). W trybie SQPOLL io_uring_enter() jest opcjonalny.
Anatomia submitowanej operacji
#include <liburing.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define QUEUE_DEPTH 256
#define BUF_SIZE 4096
int main(void) {
struct io_uring ring;
if (io_uring_queue_init(QUEUE_DEPTH, &ring, 0) < 0) {
perror("io_uring_queue_init");
exit(EXIT_FAILURE);
}
int fd = open("/data/large_file.bin", O_RDONLY);
if (fd < 0) { perror("open"); exit(EXIT_FAILURE); }
char *buf = aligned_alloc(4096, BUF_SIZE);
/* Pobierz SQE z submission queue */
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
if (!sqe) { fprintf(stderr, "SQ fulln"); exit(EXIT_FAILURE); }
/* Przygotuj operację — zero syscalli na tym etapie */
io_uring_prep_read(sqe, fd, buf, BUF_SIZE, 0);
sqe->user_data = (uint64_t)buf; /* tag korelacyjny */
/* Submit — jedyny potencjalny syscall (pominięty w SQPOLL) */
io_uring_submit(&ring);
/* Poczekaj na completion */
struct io_uring_cqe *cqe;
if (io_uring_wait_cqe(&ring, &cqe) < 0) {
perror("io_uring_wait_cqe");
exit(EXIT_FAILURE);
}
if (cqe->res < 0) {
fprintf(stderr, "Read failed: %sn", strerror(-cqe->res));
} else {
printf("Read %d bytesn", cqe->res);
}
io_uring_cqe_seen(&ring, cqe); /* zwolnij slot CQ */
io_uring_queue_exit(&ring);
free(buf);
close(fd);
return 0;
}Kluczowe: read() nigdy nie pojawia się jako osobny syscall. Operacja jest zlecona przez zapis do SQ, a kernel ją wykona i raportuje wynik do CQ. Jeden syscall io_uring_enter() może zsubmitować dowolnie wiele operacji jednocześnie — batching jest darmowy.
SQPOLL — eliminacja syscall z hot path
Flaga IORING_SETUP_SQPOLL uruchamia dedykowany wątek jądra (kthread), który ciągle poll’uje submission queue. Userspace zapisuje SQE — kthread go zauważa, wykonuje operację, zapisuje CQE. Zero syscalli w hot path.
Cena: kthread konsumuje rdzeń CPU (przechodzi w stan idle po okresie nieaktywności konfigurowalnym przez sq_thread_idle) i — od kernela 5.11 — wymaga CAP_SYS_NICE. Wcześniej był to CAP_SYS_ADMIN, co praktycznie blokowało użycie SQPOLL w procesach nieroot. Dla aplikacji absolutnie krytycznych pod kątem latencji to przełomowa zmiana.
Co dokładnie zyskujesz na poziomie syscall count
| Operacja w hot path | epoll (ET) | io_uring | io_uring + SQPOLL |
|---|---|---|---|
| Accept połączenia | 2 (epoll_wait + accept4) | 1 (io_uring_enter) | 0 |
| Read request | 2 (epoll_wait + recv) | 1 (io_uring_enter) | 0 |
| Write response | 2 (epoll_wait + send) | 1 (io_uring_enter) | 0 |
| Batched submit (N operacji) | N × 2 syscalli | 1 syscall | 0 |
| Multi-shot accept | Brak (każdy accept osobno) | 1 SQE obsługuje wiele | 0 |
Multi-shot mode (od kernela 5.13) to dodatkowa optymalizacja: jeden SQE z flagą IOSQE_BUFFER_SELECT akceptuje wszystkie nadchodzące połączenia, dopóki nie zostanie ręcznie anulowany. Dla serwerów akceptujących tysiące krótkich połączeń to kolejny rząd wielkości.
Realne liczby — czy warto?
Benchmarki publikowane przez Axboe i niezależne testy (Cloudflare, ScyllaDB, axboe/fio) konsystentnie pokazują podobny wzorzec:
- Przy < 30k req/s na rdzeń — różnica jest w granicach błędu pomiarowego. Cache effects i jakość kodu aplikacji dominują nad syscall overhead.
- Przy 50–100k req/s na rdzeń — io_uring zaczyna pokazywać przewagę ~15–25% w CPU utilization przy tej samej throughput.
- Przy > 200k req/s na rdzeń — io_uring + SQPOLL osiąga 2–3× przewagi. Tutaj epoll jest fundamentalnie wąskim gardłem.
- Dla disk I/O (random reads na NVMe) — io_uring wygrywa nawet w niskich wolumenach, bo eliminuje również narzut blokujących
read().
Inflection point to zatem ~50k req/s na rdzeń. Jeśli twój serwis robi 5k RPS na całym klastrze — io_uring jest over-engineering. Jeśli budujesz database engine, message broker, edge proxy lub serwer plików — io_uring jest właściwą odpowiedzią.
Kompatybilność i kwestie bezpieczeństwa
io_uring jest Linux-only i wymaga kernela co najmniej 5.1 (5.6+ dla production-stability, 5.11+ dla rozsądnego SQPOLL). To eliminuje:
- RHEL 7 (kernel 3.10) i RHEL 8 (kernel 4.18) — io_uring niedostępny lub w archaicznej wersji
- Kod cross-platform — kqueue na BSD, IOCP na Windows wymagają własnych ścieżek
- Niektóre środowiska kontenerowe — Google Kubernetes Engine domyślnie blokuje io_uring na poziomie seccomp ze względu na historyczne CVE (CVE-2022-1786, CVE-2023-32233 i inne)
Google publicznie wyłączył io_uring w produkcyjnych kernelach ChromeOS i Androidie. Powód: powierzchnia ataku io_uring jest znacznie szersza niż klasycznych syscalli, a kompleksowość kodu kernela obsługującego ring buffers prowadziła do wielokrotnych eskalacji uprawnień. Dla aplikacji w kontenerach na obcej infrastrukturze warto sprawdzić, czy seccomp profile w ogóle pozwala na io_uring_setup().
Dojrzałość stosu — co używać w produkcji
| Ekosystem | Biblioteka | Stan |
|---|---|---|
| C / C++ | liburing (oficjalna, Axboe) | Produkcyjny standard |
| Rust | tokio-uring, glommio | Stabilny; glommio dla thread-per-core |
| Go | Brak natywnego (Go ma własny netpoll) | CGO przez liburing — antywzorzec |
| Python | Brak dojrzałego wsparcia | Eksperymentalne bindingi, asyncio nadal na epoll |
| Node.js | Brak | libuv pozostaje na epoll |
| Erlang / Elixir | OTP 26+ — wsparcie eksperymentalne | Pre-production |
Jeśli pracujesz w Go lub Node — kompletnie zapomnij o io_uring. Te runtime’y są na epoll i nic tego nie zmieni. Dla Pythona — jeśli serwis wymaga wydajności wymagającej io_uring, język był złym wyborem na poziomie architektury.
Decision matrix — co wybrać
| Scenariusz | Wybór |
|---|---|
| HTTP API, < 50k RPS per node | epoll (nginx, uvloop, tokio) |
| Database engine, hot path I/O | io_uring (ScyllaDB, MariaDB, TiKV) |
| Storage I/O — random NVMe reads | io_uring (zysk nawet w low throughput) |
| Edge proxy > 100k connections | io_uring + SQPOLL |
| Kod cross-platform (Linux + BSD + Windows) | epoll + warstwa abstrakcji |
| Aplikacja w kontenerze z seccomp | epoll (sprawdź seccomp profile) |
| Stary kernel (RHEL 7/8, Debian 10) | epoll (brak wyboru) |
| Runtime Go / Node.js / Python (asyncio) | epoll (runtime decyduje za ciebie) |
| MVP, prototyp, internal tool | epoll bez dyskusji |
Podsumowanie: pomiar > ideologia
io_uring nie jest magiczną kulą. Jest świetnie zaprojektowanym interfejsem dla konkretnej klasy problemów — workloadów, w których narzut syscalla jest mierzalnym kosztem operacyjnym. Dla 90% aplikacji webowych, mikroserwisów i API epoll pozostaje optymalną odpowiedzią: dojrzały, dobrze rozumiany, dostępny wszędzie, kompatybilny z każdym runtime.
Inżynier który najpierw mierzy CPU profile pod produkcyjnym obciążeniem zobaczy, czy syscall overhead w ogóle pojawia się w top 10. Inżynier który od razu pisze kod na liburing, bo przeczytał o nim na Hacker News, prawdopodobnie spędzi tydzień na debugging multi-shot accept’ów dla serwisu obsługującego 800 req/s, którego nigdy nikt nie skaluje do 80k.
Premature optimization is the root of all evil — Knuth wiedział co mówił. Profilowanie przed optymalizacją to nie hasło, to inżynierska dyscyplina.
Jeśli ten poziom — konkretne syscalle i to, co dzieje się między userspace a kernelem — to Twój rejon, podobną sekcję „pod maską” ma tekst o tym, co naprawdę robi fork() w Linuksie. Wątek wydajności bez zbędnej warstwy abstrakcji ciągnie dalej materiał o cgroups v2 jako natywnym prymitywie izolacji procesów bez Dockera.