Logi mówią ci, co kod myśli, że zrobił. Stack trace mówi, gdzie kod sądził, że jest. strace mówi, co kernel naprawdę zrobił — każde openat(), każde read(), każde connect(), które zwróciło -1, podczas gdy aplikacja połknęła błąd i dalej cię okłamywała. Kiedy to właśnie rozjazd między intencją a rzeczywistością jest bugiem, kolejne czytanie źródła go nie zamknie. Musisz obserwować granicę, na której kończy się userspace, a zaczyna kernel.
Większość inżynierów zna strace -p <pid> jako przycisk paniki. Mało kto faktycznie czyta output, a jeszcze mniej sięga po -f, -c czy -k, kiedy to ma znaczenie. Ta różnica decyduje, czy gapisz się w ścianę syscalli, czy wyciągasz przyczynę źródłową w dziewięćdziesiąt sekund. Traktowanie strace jako pełnoprawnego narzędzia to bezpośrednie rozwinięcie debugowania opartego na hipotezach: formułujesz precyzyjne twierdzenie o tym, co robi proces, i pozwalasz dowodom je potwierdzić albo zabić.
Co strace naprawdę obserwuje
strace stoi na ptrace(2) — tym samym mechanizmie kernela, którego używają debuggery. Podłącza się do procesu i zatrzymuje go przy każdym przejściu przez granicę syscalla — raz na wejściu, raz na wyjściu — czytając rejestry, żeby zdekodować numer syscalla, jego argumenty i wartość zwracaną. To cały model i to on tłumaczy koszt: każdy syscall płaci teraz za dwa dodatkowe context switche do tracera. Przy obciążeniu intensywnie korzystającym z syscalli proces potrafi zwolnić o rząd wielkości. To nie przypis — to powód, dla którego strace należy do diagnostyki, nigdy do hot pathu ani do wrażliwej na latencję usługi produkcyjnej.
Czytanie linii trace’u — część, której nikt nie uczy
Każda linia ma ten sam kształt: syscall(argumenty) = wartość_zwracana. Prawda siedzi w wartości zwracanej. Udane wywołanie zwraca deskryptor pliku, liczbę bajtów albo 0; nieudane zwraca -1, a po nim symboliczny errno i jego opis. To właśnie ten errno jest sygnałem, po który przyszedłeś.
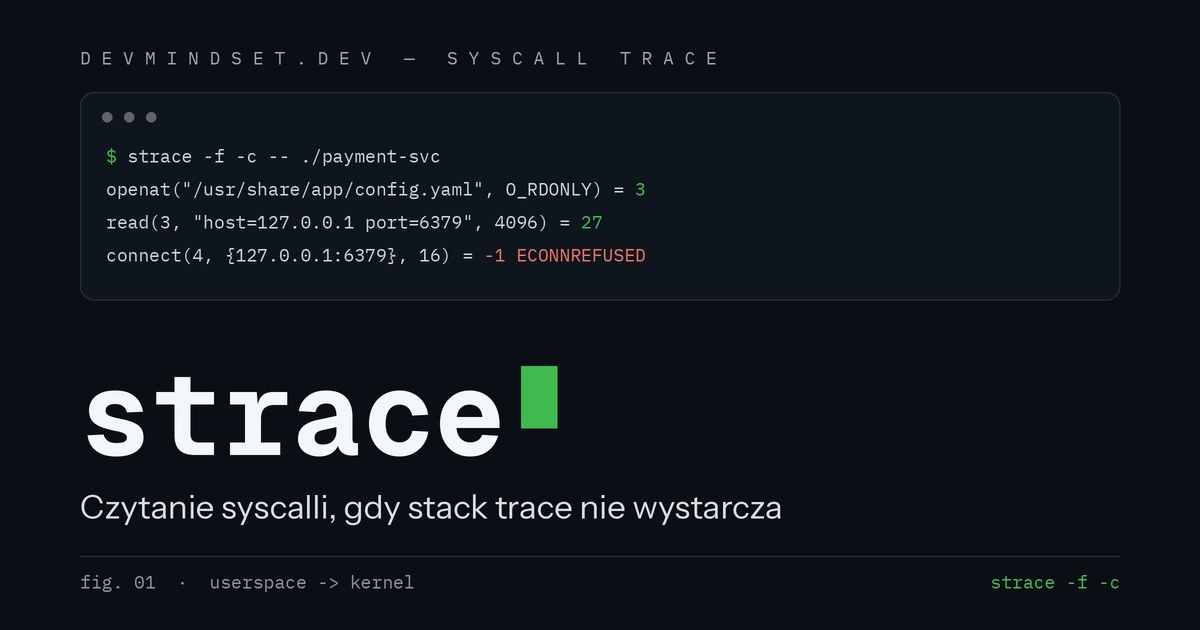
openat(AT_FDCWD, "/etc/app/config.yaml", O_RDONLY) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/share/app/config.yaml", O_RDONLY) = 3
read(3, "host: 127.0.0.1\nport: 6379\n", 4096) = 27
connect(4, {sa_family=AF_INET, sin_port=htons(6379), sin_addr=inet_addr("127.0.0.1")}, 16) = -1 ECONNREFUSED (Connection refused)Cztery linie, dwa wnioski, zero zgadywania: aplikacja sprawdziła ścieżkę konfiguracji, która nie istnieje, zanim spadła na właściwą, a połączenie z Redisem zostało wprost odrzucone. Żaden log ci tego nie powiedział — syscalle tak. Błędem wartym zapamiętania jest EFAULT: oznacza, że syscall dostał wskaźnik na pamięć, której proces nie jest właścicielem. To ta sama klasa dostępu do złego adresu, która — doprowadzona do końca przez MMU i kernel — produkuje segmentation fault.
Flagi, które oddzielają sygnał od szumu
-f— podążaj za forkami i wątkami. W momencie, gdy proces woła fork() albo odpala pulę workerów, goły trace ślepnie na dzieci. Prawie każda realna usługa potrzebuje tej flagi.-e trace=…— filtruj po klasie zamiast się topić.-e trace=network,-e trace=%file,-e trace=memorytną strumień do syscalli, które cię interesują.-c— agreguj zamiast streamować. Produkuje tabelę podsumowania: czas, liczba wywołań i błędy per syscall. To twój profiler w chwili, gdy podejrzewasz, że proces jest syscall-bound.-T/-tt— czas spędzony w każdym syscallu / absolutne znaczniki czasu. Razem zamieniają „jest wolno” w „spędza 600 ms wfsync„.-y/-yy— dekoduj deskryptory, więcread(3, …)staje sięread(3</usr/share/app/config.yaml>, …), a gniazda pokazują swoje endpointy.-k— dołącz stack trace userspace’u do każdego syscalla, łącząc „który syscall” z „którą linią kodu”.-s N— zwiększ długość drukowanych stringów (domyślnie ucina payloady).
Tryb podsumowania odpowiada też na „dlaczego to jest wolne?” bez dedykowanego profilera. Uruchom dowolne polecenie pod strace -f -c, a tabela uszereguje syscalle po skumulowanym czasie — to ta sama technika, która zamienia ślamazarny terminal w naprawialną listę winnych wywołań stat() i openat(), gdy profilujesz start shella i wydajność .bashrc.
Od surowego trace’u do działającego podsumowania
Czytanie outputu -c okiem jest OK raz. Kiedy chcesz to mieć w CI, w bramce regresyjnej albo zagregowane po wielu uruchomieniach — sparsuj to. Poniższy wrapper uruchamia polecenie pod strace -f -c, przechwytuje podsumowanie ze stderr, parsuje je do typowanych rekordów i zwraca syscalle, które dominują czas. Obsługuje oczywiste tryby awarii — brak strace, zawieszenie procesu, zepsutą tabelę — zamiast zakładać szczęśliwą ścieżkę.
from __future__ import annotations
import shutil
import subprocess
from dataclasses import dataclass
from typing import Final
_HEADER_TOKENS: Final[tuple[str, ...]] = ("seconds", "calls", "syscall")
@dataclass(frozen=True, slots=True)
class SyscallStat:
name: str
seconds: float
calls: int
errors: int
@property
def usec_per_call(self) -> float:
return (self.seconds / self.calls) * 1_000_000 if self.calls else 0.0
class StraceError(RuntimeError):
"""Podnoszony, gdy strace nie da się uruchomić lub jego podsumowania nie da się sparsować."""
def profile_syscalls(cmd: list[str], *, timeout: float = 30.0) -> list[SyscallStat]:
"""Uruchamia *cmd* pod ``strace -f -c`` i zwraca staty per syscall, od najcięższych.
Raises:
StraceError: brak strace, przekroczony timeout albo nie udało się
zlokalizować tabeli podsumowania w stderr strace'a.
"""
if not cmd:
raise StraceError("puste polecenie")
if shutil.which("strace") is None:
raise StraceError("strace nie jest zainstalowany lub nie ma go w PATH")
try:
proc = subprocess.run(
["strace", "-f", "-c", "--", *cmd],
capture_output=True,
text=True,
timeout=timeout,
check=False, # śledzony proces może legalnie zakończyć się kodem != 0
)
except subprocess.TimeoutExpired as exc:
raise StraceError(f"śledzone polecenie przekroczyło {timeout:.0f}s") from exc
return _parse_summary(proc.stderr)
def _parse_summary(stderr: str) -> list[SyscallStat]:
lines = stderr.splitlines()
header = next(
(i for i, ln in enumerate(lines) if all(t in ln for t in _HEADER_TOKENS)),
None,
)
if header is None:
raise StraceError("nie znaleziono tabeli podsumowania; czy przekazano -c do strace?")
stats: list[SyscallStat] = []
for line in lines[header + 1:]:
if not line.strip() or line.lstrip().startswith("-"):
continue
if "total" in line:
break # wiersz total kończy tabelę
cols = line.split()
if len(cols) < 5:
continue
try:
# kolumny: %time seconds usecs/call calls [errors] syscall
seconds = float(cols[1])
calls = int(cols[3])
errors = int(cols[4]) if len(cols) >= 6 and cols[4].isdigit() else 0
except (ValueError, IndexError):
continue # pomiń wszystko, co nie jest wierszem danych
stats.append(SyscallStat(name=cols[-1], seconds=seconds, calls=calls, errors=errors))
if not stats:
raise StraceError("tabela podsumowania jest, ale nie udało się sparsować wierszy")
return sorted(stats, key=lambda s: s.seconds, reverse=True)
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
raise SystemExit("użycie: profile.py POLECENIE [ARGUMENTY...]")
for stat in profile_syscalls(sys.argv[1:]):
marker = " (są błędy)" if stat.errors else ""
name = stat.name.ljust(18)
calls = str(stat.calls).rjust(8)
print(f"{name}{stat.seconds:9.4f}s {calls} wywołań {stat.usec_per_call:8.1f} us/wyw{marker}")
Jest celowo defensywny: brak binarki, timeout i nieparsowalna tabela podnoszą typowany StraceError, zamiast zwracać po cichu błędne dane. check=False jest zamierzone — śledzony program ma prawo zakończyć się kodem różnym od zera; często to jest cały powód, dla którego go śledzisz.
strace vs ltrace vs gdb vs perf — wybierz właściwą soczewkę
strace to jedna soczewka, nie jedyna. Każde narzędzie obserwuje inną warstwę za inną cenę, a sięgnięcie po niewłaściwe marnuje czas albo zaburza dokładnie to zachowanie, które ścigasz.
| Narzędzie | Obserwuje | Narzut | Najlepsze pytanie | Bezpieczne na produkcji? |
|---|---|---|---|---|
| strace | Syscalle (granica kernela) | Wysoki (2 context switche/wywołanie) | O co proces prosi kernel? | Nie — tylko diagnostyka |
| ltrace | Wywołania bibliotek (userspace) | Wysoki | Które wywołania bibliotek i z jakimi argumentami? | Nie |
| gdb | Pełny stan programu, pamięć, breakpointy | Bardzo wysoki (zatrzymuje świat) | Jaki jest dokładny stan w tej linii? | Nie (interaktywny) |
| perf trace | Syscalle przez perf_events | Niski | Jak syscalle zachowują się pod realnym obciążeniem? | Tak |
| bpftrace / eBPF | Dowolne sondy w kernelu i userspace | Bardzo niski | Własne, niskonarzutowe śledzenie na produkcji | Tak |
Kiedy nie sięgać po strace
Narzut nie jest akademicki i nie jest jedynym ograniczeniem. Na utwardzonych systemach /proc/sys/kernel/yama/ptrace_scope może zabronić podłączenia się do procesu, którego nie jesteś właścicielem — dostaniesz EPERM niezależnie od tego, jak bardzo czujesz się rootem. Wewnątrz kontenerów restrykcyjny profil seccomp może w ogóle zablokować ptrace. A na usłudze obsługującej żywy ruch podwojenie kosztu każdego syscalla to nie sesja debugowania — to incydent.
Do wszystkiego, co musi działać pod produkcyjnym obciążeniem, sięgaj po perf trace albo narzędzie eBPF w rodzaju bpftrace — obserwują tę samą granicę syscalli za ułamek kosztu. Ale na maszynie, którą kontrolujesz, z procesem, który możesz sobie pozwolić spowolnić, strace pozostaje najszybszym sposobem na odpowiedź na jedyne pytanie, które się liczy, gdy intencja rozjeżdża się z rzeczywistością: co ten proces naprawdę robi? Kiedy nauczysz się płynnie czytać jego output, to pytanie przestaje być zagadką i staje się zwykłym lookupem.