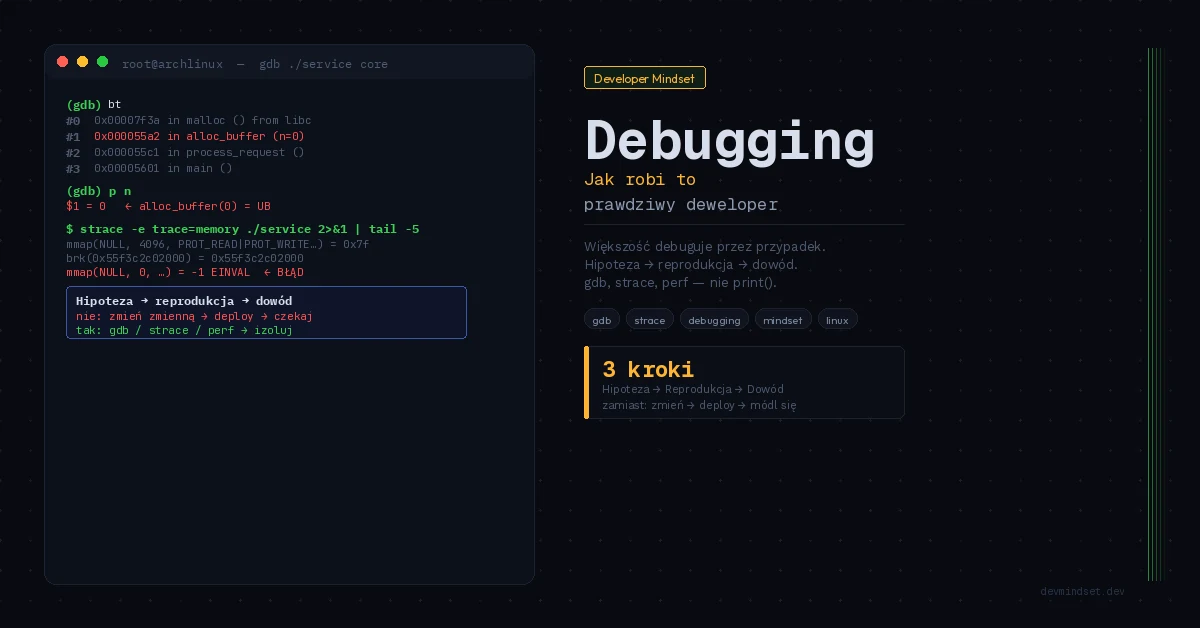
Debugowanie programisty to jedna z najważniejszych umiejętności w pracy z kodem — i jedna z najgorzej opanowanych. Masz błąd w produkcji. Patrzysz na stack trace, otwierasz plik który wskazuje linia 47 i zaczynasz grzebać. Zmieniasz jedną zmienną, deployujesz, czekasz. Nie pomogło. Zmieniasz drugą. Czekasz. Może tym razem.
To nie jest debugging. To hazard z kodem produkcyjnym.
Problem polega na tym, że większość z nas nigdy nie nauczyła się debugować — nauczyła się tylko przypadkowo naprawiać błędy. To dwie zupełnie różne rzeczy.
Debugowanie programisty metodą prób i błędów to iluzja kontroli
Wyobraź sobie lekarza, który przy każdym pacjencie przepisuje kolejne leki, aż jeden zadziała. Nie robi badań, nie stawia diagnozy — po prostu próbuje. Nazwałbyś go niekompetentnym. Tymczasem dokładnie tak samo postępuje większość programistów przy debugowaniu.
Klasyczne objawy złego debugowania:
- Dodajesz
console.loglubprint()w losowych miejscach kodu - Zmieniasz kilka rzeczy naraz, bo „może któraś z nich to naprawi”
- Szukasz na Stack Overflow zanim w pełni zrozumiesz błąd
- Restartujesz serwis „żeby zobaczyć czy pomaga”
- Opisujesz problem jako „coś się psuje” zamiast konkretnego zachowania
Każdy z tych nawyków ma jeden wspólny mianownik: działasz bez hipotezy. Bez hipotezy nie debugujesz — zgadujesz.
Jak myśli programista, który naprawdę debuguje
Debugowanie programisty to proces dedukcji, nie eksploracji. Różnica jest fundamentalna.
Eksploracja oznacza: „Nie wiem co jest źle, więc będę grzebać aż znajdę.”
Dedukcja oznacza: „Wiem jak system powinien działać. Obserwuję jak działa. Różnica między oczekiwaniem a obserwacją to mój punkt startowy.”
Zanim dotkniesz kodu, musisz odpowiedzieć na trzy pytania:
1. Jakie jest dokładne, powtarzalne zachowanie systemu?
Nie „coś się psuje przy logowaniu”. Konkretnie: „Użytkownik z emailem zawierającym znak + nie może się zalogować. Błąd pojawia się wyłącznie przy metodzie OAuth, nie przy logowaniu hasłem. Reprodukuję na środowisku staging, nie reprodukuję lokalnie.”
Im precyzyjniej opisujesz problem, tym szybciej go rozwiążesz. To nie pedanteria — to podstawowa higiena debugowania.
2. Jakie jest Twoje oczekiwane zachowanie i skąd to wiesz?
Musisz mieć punkt odniesienia. Czy masz dokumentację? Testy? Poprzedni commit gdzie działało? Bez odpowiedzi na to pytanie nie wiesz nawet czego szukasz.
3. Jaka jest Twoja hipoteza?
Jedna konkretna hipoteza, zanim zaczniesz cokolwiek zmieniać. „Podejrzewam że URL encoder w bibliotece X nie obsługuje znaku + w parametrze email.” Następnie weryfikujesz tę hipotezę — i tylko tę hipotezę. Jeśli okazuje się fałszywa, formujesz kolejną.
Narzędzia które zmieniają perspektywę
Większość programistów używa debuggera jak latarki w ciemnym pokoju — świecą gdzie popadnie. Debugger to narzędzie do weryfikacji hipotez, nie do ich generowania.
Binary search na kodzie
Kiedy nie wiesz gdzie jest błąd, nie zaczynasz od początku pliku. Stawiasz breakpoint w połowie ścieżki wykonania. Błąd pojawia się przed czy po? Eliminujesz połowę problemu w jednym kroku. Powtarzasz. To jest O(log n) debugging zamiast O(n).
Izolacja zmiennych
Każda zmiana w środowisku to potencjalna przyczyna. Zanim zaczniesz szukać w kodzie, zadaj pytanie: co się zmieniło od ostatniego momentu kiedy działało? Nowa wersja biblioteki? Zmiana konfiguracji? Migracja bazy danych? Commit sprzed tygodnia?
git bisect to jedno z najbardziej niedocenianych narzędzi w ekosystemie deweloperskim — pozwala binarnie przeszukać historię commitów i znaleźć dokładny commit który wprowadził regresję. Większość programistów nawet go nie zna.
Logi jako narracja, nie jako szum
Logi czytasz jak detektyw czyta zeznania świadków — szukasz niespójności, nie potwierdzenia swojej teorii. Jeśli logujesz tylko błędy, ślepy jesteś na to co dzieje się tuż przed błędem. Dobry log to kontekst: kto, co, kiedy, z jakimi danymi wejściowymi.
Błąd który kosztuje godziny: debugowanie objawu zamiast przyczyny
Stack trace wskazuje linię 203. Idziesz do linii 203 i zaczynasz tam szukać. To błąd.
Linia 203 to miejsce gdzie system krzyczy — nie miejsce gdzie popełniono zbrodnię. Błąd logiczny często pojawia się 10, 20, 50 linii wcześniej, w miejscu gdzie dane wchodzą do systemu w złym stanie. Linia 203 tylko jako pierwsza nie daje rady z tym poradzić.
Naucz się czytać stack trace od góry, ale myśleć o nim od dołu. Gdzie dane weszły do systemu? Co miały zawierać? Co zawierają faktycznie? Gdzieś między wejściem a objawem leży przyczyna.
Kiedy utknąłeś: technika gumowej kaczki
Masz 45 minut w problemie i nic. Nie otwieraj Stack Overflow. Zamiast tego wytłumacz problem na głos — dosłownie, słowami — komukolwiek obok. Albo gumowej kaczce na biurku. Albo plikowi tekstowemu.
To nie jest żart. Kiedy zmuszasz się do linearnego, słownego opisu problemu, Twój mózg przetwarza go inaczej niż podczas wizualnego przeglądania kodu. W 60% przypadków rozwiązanie pojawi się w trakcie tłumaczenia, zanim skończyłeś zdanie.
Jeśli nie masz do kogo mówić, pisz. GitHub Issues, Slack do siebie samego, notatnik. Pełny opis problemu: co widzisz, czego oczekujesz, co już sprawdziłeś, jaka jest Twoja aktualna hipoteza.
Czego nie ma w tym wpisie — i dlaczego
Nie znajdziesz tutaj listy narzędzi do debugowania z opisem każdego skrótu klawiszowego. Nie dlatego że narzędzia są nieważne — dlatego że złe podejście z lepszym narzędziem daje tylko szybsze złe wyniki.
Narzędzia to osobny temat, na osobny artykuł.
Skuteczne debugowanie programisty zaczyna się zawsze od
precyzyjnego opisu problemu — nie od otwierania pliku.
Co zrobić inaczej od dziś
Następnym razem gdy trafisz na błąd, zanim dotkniesz kodu — napisz w komentarzu lub pliku tekstowym trzy zdania:
- Dokładne, powtarzalne zachowanie które obserwujesz.
- Dokładne zachowanie które oczekujesz i skąd to wiesz.
- Twoja pierwsza hipoteza o przyczynie.
Jeśli nie możesz napisać tych trzech zdań, nie jesteś gotowy do debugowania. Wróć do obserwacji systemu.
To nawyk, który oddziela programistów którzy „jakoś to naprawiają” od tych, którzy rozumieją co naprawiają i dlaczego.
Metodyczne dochodzenie do przyczyny ma swój najbardziej namacalny przypadek w analizie awarii pamięci — rozkłada ją na czynniki pierwsze tekst o anatomii segfaulta, od MMU przez kernel po core dump w gdb. Sama umiejętność dedukcji, na której opiera się cały ten proces, zaczyna się zaś od czytania cudzego kodu szybciej, niż napisałeś własny — bo w obu przypadkach budujesz model systemu, zanim go dotkniesz.