DRY jako kult — i jego ukryty koszt
„Don’t Repeat Yourself” stało się religijnym dogmatem branży. Każdy junior po pierwszym tygodniu czytania Clean Code tropi duplikację jak inkwizytor herezję. Każde code review zawiera komentarz: „to wygląda jak duplikacja, wyciągnij to do wspólnej funkcji”. Każdy linter ma regułę pokrewną typu no-duplicate-string.
Tymczasem to nie DRY zabija codebase’y. Premature abstraction zabija codebase’y. Cytując Sandi Metz: „duplication is far cheaper than the wrong abstraction” — i to zdanie powinno wisieć w każdym pokoju architektonicznym obok zasad SOLID, jako kontrapunkt.
Ten artykuł rozkłada moment, w którym pogoń za DRY przestaje być inżynierią, a staje się długiem technicznym o nieoczywistym oprocentowaniu. Pokazuje, jak rozpoznać fake duplication (przypadkową zbieżność) versus real duplication (powtórzenie tego samego konceptu domenowego) i kiedy świadomie zostawić skopiowane 30 linii w trzech miejscach.
Pierwotny kontekst DRY — i jak został wypaczony
Andy Hunt i Dave Thomas w The Pragmatic Programmer (1999) sformułowali DRY w bardzo precyzyjny sposób:
„Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.”
Słowo klucz: knowledge. Nie kod. Nie składnia. Wiedza domenowa.
Jeśli reguła biznesowa „VAT wynosi 23%” jest powielona w pięciu miejscach — to jest naruszenie DRY. Jeśli pięć różnych funkcji ma akurat trzy podobne linijki kodu obliczające coś innego, ale w podobnej strukturze — to nie jest naruszenie DRY. To jest syntaktyczna zbieżność, a wyciągnięcie tego do wspólnej funkcji wytworzy fałszywą abstrakcję.
Anatomia fałszywej abstrakcji
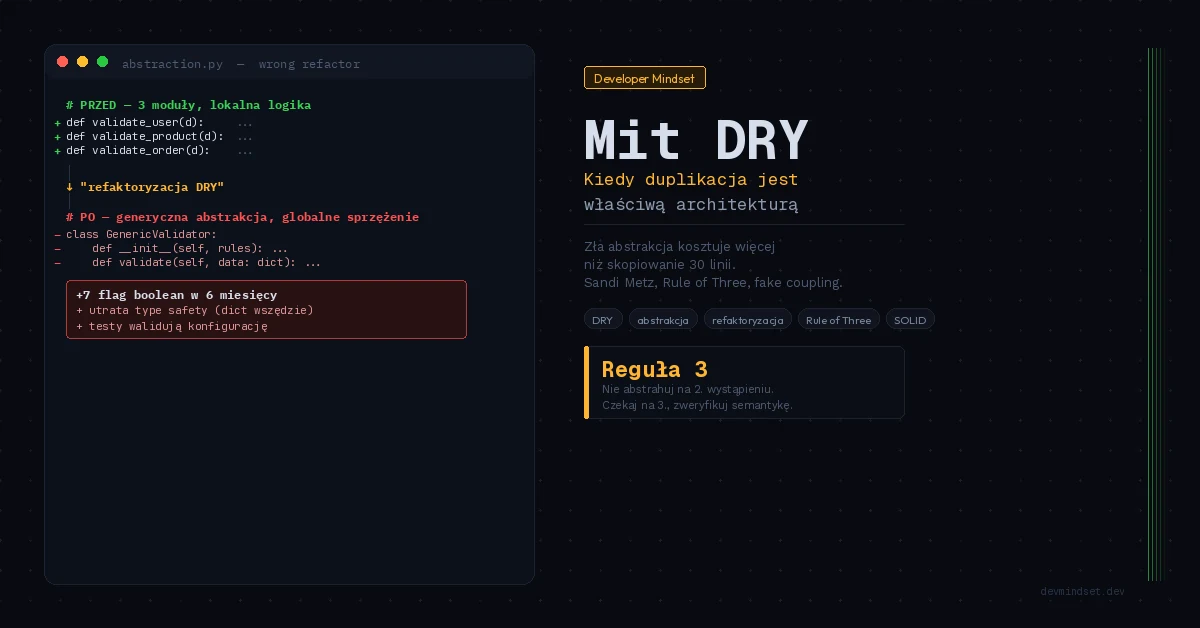
Rozważmy realistyczny scenariusz. System e-commerce. Trzy moduły mają funkcje walidujące dane wejściowe:
# module: user_registration.py
def validate_user_data(data: dict) -> ValidationResult:
errors = []
if not data.get("email"):
errors.append("Email is required")
if len(data.get("password", "")) < 8:
errors.append("Password too short")
if not data.get("terms_accepted"):
errors.append("Terms must be accepted")
return ValidationResult(valid=not errors, errors=errors)
# module: product_creation.py
def validate_product_data(data: dict) -> ValidationResult:
errors = []
if not data.get("name"):
errors.append("Name is required")
if data.get("price", 0) <= 0:
errors.append("Price must be positive")
if not data.get("category_id"):
errors.append("Category is required")
return ValidationResult(valid=not errors, errors=errors)
# module: order_submission.py
def validate_order_data(data: dict) -> ValidationResult:
errors = []
if not data.get("user_id"):
errors.append("User is required")
if not data.get("items"):
errors.append("Order must contain items")
if data.get("total", 0) <= 0:
errors.append("Total must be positive")
return ValidationResult(valid=not errors, errors=errors)Każdy nadgorliwy reviewer zobaczy tu duplikację. Pojawi się PR refaktoringujący to do jednej klasy GenericValidator z konfiguracją regułową:
class GenericValidator:
"""
Don't actually do this. This is what fake abstraction looks like.
"""
def __init__(self, rules: list[ValidationRule]) -> None:
self._rules = rules
def validate(self, data: dict) -> ValidationResult:
errors = [
rule.error_message
for rule in self._rules
if not rule.check(data)
]
return ValidationResult(valid=not errors, errors=errors)
# Now usage looks like:
USER_VALIDATOR = GenericValidator([
RequiredFieldRule("email", "Email is required"),
MinLengthRule("password", 8, "Password too short"),
BooleanTrueRule("terms_accepted", "Terms must be accepted"),
])Wygląda profesjonalnie. Wygląda DRY-compliant. Jest pułapką.
Co właśnie zostało zniszczone
Po refaktoringu:
- Reguły walidacji nie mogą rosnąć niezależnie. Gdy user_registration potrzebuje walidacji
email_domain_blacklist, której nie ma sensu używać nigdzie indziej, dodajemy ją do współdzielonegoGenericValidator. Klasa generyczna zaczyna obrastać kontekstem domenowym, który zaprzecza jej generyczności. - Sygnatury typów stają się anemiczne.
dictjako wejście oznacza utratę type safety. Wcześniej można było użyćUserRegistrationDTO; teraz wszystko jest dict-em. - Każda zmiana wymaga rozumienia globalnego. Modyfikacja walidacji rejestracji wymaga zrozumienia, czy nie zepsuje walidacji produktu, bo dzielą tę samą warstwę abstrakcji.
- Testy stają się testami konfiguracji. Zamiast testować logikę biznesową walidacji, testujesz, czy konfiguracja reguł jest poprawna. To zupełnie inny rodzaj testu — i znacznie mniej wartościowy.
Cytując ponownie Sandi Metz: „prefer duplication over the wrong abstraction”. Kod przed refaktoringiem był czytelny w pojedynczym zakresie. Każda funkcja walidacyjna była samodzielna, miała pełny kontekst i można ją było zmieniać bez konsekwencji.
Reguła Three Strikes — kiedy abstrakcja jest gotowa
Don Roberts sformułował klasyczną heurystykę:
„The first time you do something, you just do it. The second time you do something similar, you wince at the duplication, but you do the duplicate thing anyway. The third time you do something similar, you refactor.”
Reguła Rule of Three nie jest arbitralna. Ma głębokie uzasadnienie statystyczne: z dwóch punktów danych nie da się ekstrapolować trendu. Dopiero trzecie wystąpienie pokazuje, czy „duplikacja” reprezentuje rzeczywisty wzorzec, czy przypadkową zbieżność.
Refaktoryzacja na drugim wystąpieniu („o, mamy to dwa razy, wyciągnijmy”) jest statystycznie naiwna. Bo gdy trzecie wystąpienie się pojawi i będzie się prawie zgadzać z abstrakcją, ale wymagać jednej specjalnej flagi — i tu zaczyna się rak parametrów.
Anti-Pattern: Boolean Flag Cancer
Klasyczny objaw zbyt wczesnej abstrakcji. Funkcja, która kiedyś robiła jedno, teraz przyjmuje rosnący zestaw flag:
def process_order(
order: Order,
skip_inventory_check: bool = False,
skip_payment: bool = False,
is_b2b: bool = False,
is_subscription: bool = False,
bypass_fraud_check: bool = False,
legacy_pricing_mode: bool = False,
use_new_tax_calculator: bool = True,
) -> OrderResult:
# 200 lines of branching hell
...Każda flaga to ślad po wymuszonym ponownym użyciu kodu, który powinien był pozostać oddzielną funkcją. Każda kombinacja flag to potencjalna ścieżka wykonania, której nikt nigdy nie przetestuje. Test coverage w stosunku do cyclomatic complexity rośnie wykładniczo, ale w praktyce większość ścieżek jest martwych.
Diagnoza: tę funkcję trzeba rozbić z powrotem na osobne funkcje. process_b2b_subscription_order(), process_one_off_consumer_order() — nazwane intencją, nie konfiguracją.
Tabela decyzyjna: DRY czy duplikacja?
| Sytuacja | DRY | Zostaw duplikację |
|---|---|---|
| Reguła biznesowa (stawka VAT, limit konta, polityka rabatowa) | ✅ Zawsze | ❌ |
| Constant magiczny (timeout, max_retries, port) | ✅ Zawsze | ❌ |
| Format danych (schema API, struktura DB) | ✅ Zawsze (single source of truth) | ❌ |
| Podobny szkielet kodu w 2 miejscach, różne intencje | ❌ Premature | ✅ Czekaj na 3. wystąpienie |
| Walidacja dwóch różnych encji domenowych | ❌ Sprzęga niezależne moduły | ✅ Każda encja ma własną |
| „Wygląda podobnie” ale ma inne ścieżki zmian | ❌ Coupling fałszywy | ✅ Niezależna ewolucja |
| 3+ wystąpień z identyczną semantyką i identycznymi ścieżkami zmian | ✅ Refaktoruj | ❌ |
| Utility funkcje czysto syntaktyczne (date formatting, string padding) | ✅ Wyciągnij do shared utils | ❌ |
Test heurystyczny: kiedy abstrakcja jest właściwa
Przed wyciągnięciem wspólnego kodu zadaj sobie cztery pytania:
- Czy oba miejsca będą zmieniały się z tego samego powodu? Jeśli nie — duplikacja jest przypadkowa, nie wyciągaj. (Single Responsibility Principle, sformułowany przez Roberta Martina jako: „a module should have one and only one reason to change”).
- Czy potrafię nazwać tę abstrakcję bez słowa „Generic”, „Common”, „Util”, „Helper”, „Base”? Jeśli nie — brakuje ci pojęcia domenowego. Nie ma abstrakcji bez nazwy oddającej intencję.
- Czy mogę zmienić jedną z duplikacji bez patrzenia na pozostałe? Jeśli tak, duplikacja kupuje ci lokalną niezależność rozumowania. To wartość, nie wada.
- Czy oba miejsca były razem w tym samym module domenowym? Jeśli pochodzą z różnych bounded contexts (terminologia z DDD) — duplikacja jest właściwa. Współdzielenie kodu między bounded contexts to sprzęganie kontekstów.
Cztery razy „tak” → refaktoryzacja jest dobrym ruchem. Choćby jedno „nie” → zostaw kod w spokoju.
Konkretny przykład: kiedy ta sama linia kodu w dwóch miejscach jest właściwa
# auth/jwt_validator.py
def validate_jwt(token: str) -> UserClaims:
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=["HS256"])
except jwt.ExpiredSignatureError:
raise AuthenticationError("Token expired")
except jwt.InvalidTokenError as exc:
raise AuthenticationError(f"Invalid token: {exc}")
return UserClaims(**payload)
# webhooks/signature_validator.py
def validate_webhook_jwt(token: str) -> WebhookClaims:
try:
payload = jwt.decode(token, WEBHOOK_SECRET, algorithms=["HS256"])
except jwt.ExpiredSignatureError:
raise WebhookValidationError("Webhook token expired")
except jwt.InvalidTokenError as exc:
raise WebhookValidationError(f"Invalid webhook token: {exc}")
return WebhookClaims(**payload)„Ależ to identyczny kod!” — krzyknie reviewer.
Nie. To są dwa różne konteksty bezpieczeństwa z różnymi sekretami, różnymi typami wyjątków i różnymi modelami claims. Łączenie ich w jedną funkcję validate_any_jwt(token, secret, claims_class, error_class) stworzy zależność krzyżową, którą później ktoś rozszerzy o „tylko jedną” flagę asymetrycznej kryptografii dla webhooków, a potem o „tylko jeden” custom claim dla user JWT, i za rok będzie miał funkcję z 12 parametrami.
Dwa moduły, dwa konteksty, dwie odpowiedzialności. Identyczny szkielet to tylko cecha sygnatury JWT, nie powód do sprzęgania.
Kiedy DRY jest absolutnie konieczne
Ten artykuł nie jest manifestem anty-DRY. Istnieją sytuacje, w których duplikacja jest katastrofą i każda godzina jej tolerowania to dług techniczny rosnący wykładniczo:
- Schema bazy danych i odpowiadające jej DTO/encje — jedno źródło prawdy, zawsze. Code generation z migracji, nie ręczne synchronizowanie.
- API contracts między serwisami — OpenAPI/Protobuf/GraphQL schema jako single source of truth, oba końce generowane z tego samego pliku.
- Constants konfiguracyjne — żadnego magic stringa „production” w 47 miejscach, jedno
Environment.PRODUCTION. - Reguły biznesowe podlegające zmianom przepisowym — stawki podatkowe, limity transakcji, polityki KYC. Te muszą być w jednym miejscu, bo prawnik nie będzie przeszukiwał codebase’u, gdy zmienia się ustawa.
To są przypadki real knowledge duplication — naruszenie pierwotnej definicji DRY z Pragmatic Programmer.
Podsumowanie: rzemiosło, nie ideologia
Inżynieria oprogramowania nie polega na maksymalizacji metryki „linijek bez powtórzeń”. Polega na minimalizacji długoterminowego kosztu zmiany. Czasem ten koszt jest niższy przy duplikacji, czasem przy abstrakcji — i to inżynier musi rozróżnić, nie linter.
Dwie zasady do zapamiętania, gdy następnym razem zobaczysz „podobny kod”:
- Rule of Three — nie abstrahuj na drugim wystąpieniu. Czekaj na trzecie i sprawdź, czy naprawdę mają tę samą semantykę.
- Wrong abstraction kosztuje więcej niż duplikacja — bo abstrakcję trudniej cofnąć niż skopiować 30 linii.
Programiści, którzy to rozumieją, projektują systemy, które ewoluują. Programiści, którzy ścigają DRY jak dogmat, projektują systemy, które się usztywniają — aż dług abstrakcji wymusza przepisanie od zera.
Rozróżnienie między realną a pozorną duplikacją widać najwyraźniej, gdy czytasz cudzy kod szybciej, niż napisałeś własny — bo to wtedy oceniasz, które abstrakcje faktycznie niosą wartość. Ta sama trzeźwość wobec dogmatów przydaje się w debugowaniu, gdzie liczy się hipoteza, nie odruch.