DRY as a Cult — and Its Hidden Cost
“Don’t Repeat Yourself” has become a religious dogma in the industry. Every junior who has spent a week reading Clean Code hunts duplication like an inquisitor hunting heresy. Every code review contains the comment: “this looks like duplication, extract it into a shared function”. Every linter has a related rule like no-duplicate-string.
Yet it isn’t DRY that kills codebases. Premature abstraction kills codebases. Quoting Sandi Metz: “duplication is far cheaper than the wrong abstraction” — and that sentence should hang in every architecture room next to the SOLID principles, as a counterpoint.
This article dissects the moment when chasing DRY stops being engineering and becomes technical debt with non-obvious compound interest. It shows how to recognize fake duplication (incidental similarity) versus real duplication (the same domain concept repeated), and when to consciously leave 30 copied lines in three places.
The Original Context of DRY — and How It Was Twisted
Andy Hunt and Dave Thomas, in The Pragmatic Programmer (1999), formulated DRY very precisely:
“Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.”
The key word: knowledge. Not code. Not syntax. Domain knowledge.
If the business rule “VAT is 23%” is duplicated in five places — that’s a DRY violation. If five different functions happen to have three similar lines of code calculating something different but in a similar structure — that’s not a DRY violation. That’s syntactic similarity, and extracting it into a shared function will produce fake abstraction.
Anatomy of a Fake Abstraction
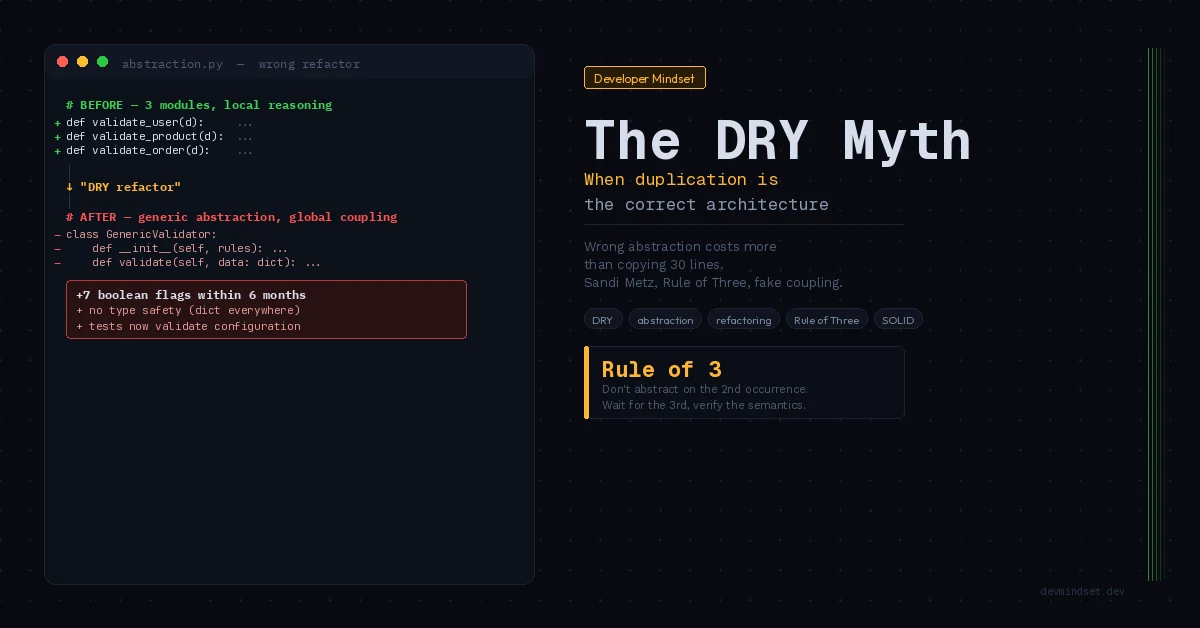
Consider a realistic scenario. An e-commerce system. Three modules with input validation functions:
# module: user_registration.py
def validate_user_data(data: dict) -> ValidationResult:
errors = []
if not data.get("email"):
errors.append("Email is required")
if len(data.get("password", "")) < 8:
errors.append("Password too short")
if not data.get("terms_accepted"):
errors.append("Terms must be accepted")
return ValidationResult(valid=not errors, errors=errors)
# module: product_creation.py
def validate_product_data(data: dict) -> ValidationResult:
errors = []
if not data.get("name"):
errors.append("Name is required")
if data.get("price", 0) <= 0:
errors.append("Price must be positive")
if not data.get("category_id"):
errors.append("Category is required")
return ValidationResult(valid=not errors, errors=errors)
# module: order_submission.py
def validate_order_data(data: dict) -> ValidationResult:
errors = []
if not data.get("user_id"):
errors.append("User is required")
if not data.get("items"):
errors.append("Order must contain items")
if data.get("total", 0) <= 0:
errors.append("Total must be positive")
return ValidationResult(valid=not errors, errors=errors)Any overzealous reviewer will see duplication. A PR will appear refactoring this into a single GenericValidator class with rule-based configuration:
class GenericValidator:
"""
Don't actually do this. This is what fake abstraction looks like.
"""
def __init__(self, rules: list[ValidationRule]) -> None:
self._rules = rules
def validate(self, data: dict) -> ValidationResult:
errors = [
rule.error_message
for rule in self._rules
if not rule.check(data)
]
return ValidationResult(valid=not errors, errors=errors)
# Now usage looks like:
USER_VALIDATOR = GenericValidator([
RequiredFieldRule("email", "Email is required"),
MinLengthRule("password", 8, "Password too short"),
BooleanTrueRule("terms_accepted", "Terms must be accepted"),
])It looks professional. It looks DRY-compliant. It’s a trap.
What Just Got Destroyed
After the refactor:
- Validation rules can no longer evolve independently. When user_registration needs
email_domain_blacklistvalidation that makes no sense anywhere else, you add it to the sharedGenericValidator. The generic class starts accumulating domain context that contradicts its genericity. - Type signatures become anemic.
dictas input means losing type safety. Previously, you could useUserRegistrationDTO; now everything is a dict. - Every change requires global reasoning. Modifying registration validation requires understanding whether it breaks product validation, because they share the same abstraction layer.
- Tests become configuration tests. Instead of testing business validation logic, you test whether rule configuration is correct. That’s a fundamentally different kind of test — and significantly less valuable.
Quoting Sandi Metz again: “prefer duplication over the wrong abstraction”. The pre-refactor code was readable in a single scope. Each validation function was self-contained, had full context, and could be changed without consequences elsewhere.
The Rule of Three — When the Abstraction Is Ready
Don Roberts formulated the classical heuristic:
“The first time you do something, you just do it. The second time you do something similar, you wince at the duplication, but you do the duplicate thing anyway. The third time you do something similar, you refactor.”
The Rule of Three isn’t arbitrary. It has deep statistical justification: you can’t extrapolate a trend from two data points. Only the third occurrence reveals whether the “duplication” represents a real pattern or accidental similarity.
Refactoring on the second occurrence (“oh, we have this twice, let’s extract it”) is statistically naive. Because when the third occurrence appears and almost matches the abstraction, but requires one special flag — that’s where parameter cancer begins.
Anti-Pattern: Boolean Flag Cancer
A classic symptom of premature abstraction. A function that once did one thing now accepts a growing set of flags:
def process_order(
order: Order,
skip_inventory_check: bool = False,
skip_payment: bool = False,
is_b2b: bool = False,
is_subscription: bool = False,
bypass_fraud_check: bool = False,
legacy_pricing_mode: bool = False,
use_new_tax_calculator: bool = True,
) -> OrderResult:
# 200 lines of branching hell
...Each flag is a scar left by forced code reuse that should have remained a separate function. Each flag combination is a potential execution path no one will ever test. Test coverage versus cyclomatic complexity grows exponentially, but in practice most paths are dead code.
Diagnosis: this function needs to be broken back apart into separate functions. process_b2b_subscription_order(), process_one_off_consumer_order() — named by intent, not by configuration.
Decision Matrix: DRY or Duplication?
| Situation | DRY | Keep Duplication |
|---|---|---|
| Business rule (VAT rate, account limit, discount policy) | ✅ Always | ❌ |
| Magic constant (timeout, max_retries, port) | ✅ Always | ❌ |
| Data format (API schema, DB structure) | ✅ Always (single source of truth) | ❌ |
| Similar code skeleton in 2 places, different intents | ❌ Premature | ✅ Wait for 3rd occurrence |
| Validation of two different domain entities | ❌ Couples independent modules | ✅ Each entity owns its validation |
| “Looks similar” but has different change paths | ❌ False coupling | ✅ Independent evolution |
| 3+ occurrences with identical semantics and identical change paths | ✅ Refactor | ❌ |
| Utility functions purely syntactic (date formatting, string padding) | ✅ Extract to shared utils | ❌ |
Heuristic Test: When Abstraction Is Appropriate
Before extracting shared code, ask yourself four questions:
- Will both places change for the same reason? If not — duplication is incidental, don’t extract. (Single Responsibility Principle, formulated by Robert Martin as: “a module should have one and only one reason to change”).
- Can I name this abstraction without using “Generic”, “Common”, “Util”, “Helper”, “Base”? If not — you lack a domain concept. There’s no abstraction without a name that reflects intent.
- Can I change one of the duplications without looking at the others? If yes, duplication buys you local reasoning independence. That’s value, not waste.
- Are both places within the same domain module? If they come from different bounded contexts (DDD terminology) — duplication is correct. Sharing code between bounded contexts means coupling contexts.
Four “yes” answers → refactoring is a good move. A single “no” → leave the code alone.
Concrete Example: When the Same Line of Code in Two Places Is Correct
# auth/jwt_validator.py
def validate_jwt(token: str) -> UserClaims:
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=["HS256"])
except jwt.ExpiredSignatureError:
raise AuthenticationError("Token expired")
except jwt.InvalidTokenError as exc:
raise AuthenticationError(f"Invalid token: {exc}")
return UserClaims(**payload)
# webhooks/signature_validator.py
def validate_webhook_jwt(token: str) -> WebhookClaims:
try:
payload = jwt.decode(token, WEBHOOK_SECRET, algorithms=["HS256"])
except jwt.ExpiredSignatureError:
raise WebhookValidationError("Webhook token expired")
except jwt.InvalidTokenError as exc:
raise WebhookValidationError(f"Invalid webhook token: {exc}")
return WebhookClaims(**payload)“But that’s identical code!” — the reviewer will shout.
No. These are two different security contexts with different secrets, different exception types, and different claims models. Merging them into one function validate_any_jwt(token, secret, claims_class, error_class) creates cross-cutting dependency that someone will later extend with “just one” asymmetric-crypto flag for webhooks, then “just one” custom claim for user JWTs, and a year later have a function with 12 parameters.
Two modules, two contexts, two responsibilities. The identical skeleton is just a characteristic of the JWT signature, not a reason to couple.
When DRY Is Absolutely Necessary
This article is not an anti-DRY manifesto. There are situations where duplication is catastrophic, and every hour of tolerating it is technical debt growing exponentially:
- Database schema and corresponding DTOs/entities — single source of truth, always. Code generation from migrations, not manual synchronization.
- API contracts between services — OpenAPI/Protobuf/GraphQL schema as single source of truth, both endpoints generated from the same file.
- Configuration constants — no magic string “production” in 47 places, one
Environment.PRODUCTION. - Business rules subject to regulatory change — tax rates, transaction limits, KYC policies. These must live in one place, because a lawyer won’t grep the codebase when legislation changes.
These are cases of real knowledge duplication — violations of the original DRY definition from Pragmatic Programmer.
Conclusion: Craftsmanship, Not Ideology
Software engineering isn’t about maximizing the “lines without repetition” metric. It’s about minimizing the long-term cost of change. Sometimes that cost is lower under duplication, sometimes under abstraction — and it’s the engineer’s job to distinguish, not the linter’s.
Two rules to remember when you next see “similar code”:
- Rule of Three — don’t abstract on the second occurrence. Wait for the third and verify they actually share the same semantics.
- Wrong abstraction costs more than duplication — because abstraction is harder to reverse than copying 30 lines.
Engineers who understand this design systems that evolve. Engineers who chase DRY as dogma design systems that calcify — until the abstraction debt forces a rewrite from scratch.
The line between real and apparent duplication is clearest when you read other people’s code faster than you wrote your own — because that’s when you judge which abstractions actually carry their weight. The same skepticism toward dogma pays off in debugging, where a hypothesis beats a reflex.