The Overhead Tax of Container Abstraction
Every time a team reaches for Docker to isolate a background service—a scheduled job, a data pipeline, a monitoring daemon—it pays an overhead tax. The container runtime (containerd, runc) must initialize a namespaced environment, mount overlay filesystems, and manage network virtualization, even when the only requirement is CPU throttling and memory capping for a single process.cgroups v2 (Control Groups version 2), unified in Linux 4.5 and enabled by default on most modern distributions including Arch Linux since kernel 5.8+, provides that isolation primitive natively—with zero daemon overhead, no image layers, no OCI spec compliance ceremony.This article dissects the operational architecture of the cgroups v2 unified hierarchy, its integration with systemd’s transient unit model, and programmatic control via Python—delivering the isolation contract without the abstraction tax.cgroups v2: Architectural Shift from v1
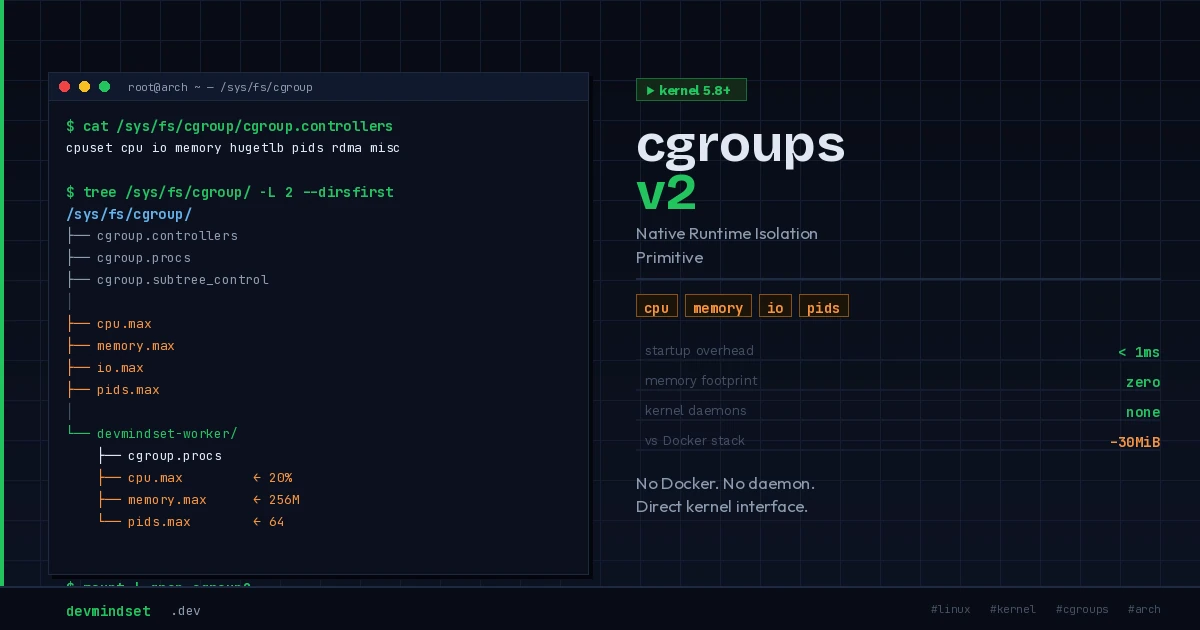
The fundamental flaw of cgroups v1 was its fragmented, per-controller hierarchy. CPU limits lived in/sys/fs/cgroup/cpu/, memory limits in /sys/fs/cgroup/memory/—independent trees that could produce conflicting resource assignments and made atomic process migration across controllers operationally fragile.cgroups v2 enforces a single, unified hierarchy rooted at /sys/fs/cgroup/. All controllers—cpu, memory, io, pids—operate within one coherent tree. The key architectural invariant: a process can belong to exactly one cgroup.Unified Hierarchy Verification
# Verify cgroups v2 is the active mode
$ mount | grep cgroup
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
# Inspect available controllers on root cgroup
$ cat /sys/fs/cgroup/cgroup.controllers
cpuset cpu io memory hugetlb pids rdma misccgroup2 as the filesystem type and a unified set of controllers, the system is fully migrated. On hybrid systems, the cgroup_no_v1=all kernel parameter forces exclusive v2 mode.Direct Cgroup Lifecycle Management
Cgroup management at its core is filesystem manipulation. Creating a cgroup means creating a directory; assigning a process means writing its PID tocgroup.procs; constraining resources means writing values to controller-specific interface files.Creating and Configuring a Cgroup
# Create a cgroup for an isolated workload
$ mkdir /sys/fs/cgroup/devmindset-worker
# Enable CPU and memory controllers on this cgroup
$ echo "+cpu +memory" > /sys/fs/cgroup/devmindset-worker/cgroup.subtree_control
# Cap CPU utilization: 20% of one core (quota/period in microseconds)
$ echo "20000 100000" > /sys/fs/cgroup/devmindset-worker/cpu.max
# Hard memory limit: 256 MiB
$ echo $((256 * 1024 * 1024)) > /sys/fs/cgroup/devmindset-worker/memory.max
# Assign current shell process to the cgroup
$ echo $$ > /sys/fs/cgroup/devmindset-worker/cgroup.procscpu.max interface accepts $QUOTA $PERIOD pairs, directly mapping to CFS (Completely Fair Scheduler) bandwidth throttling. Any process inside this cgroup consuming more than 20ms per 100ms window will be throttled at the scheduler level—no userspace daemon required.Systemd Integration: Transient Units as Isolation Primitive
For production workloads on systemd-based systems,systemd-run is the idiomatic abstraction over cgroups v2. It spawns a process inside a transient systemd scope or service unit, inheriting the systemd cgroup delegation model.# Launch an isolated process with resource constraints via transient unit
$ systemd-run
--scope
--unit=devmindset-worker
--property=CPUQuota=20%
--property=MemoryMax=256M
--property=IOWeight=10
/usr/bin/python3 /opt/workers/pipeline_runner.py
# Inspect live resource accounting
$ systemctl status devmindset-worker.scope
$ cat /sys/fs/cgroup/system.slice/devmindset-worker.scope/cpu.stat--scope flag creates a transient unit scoped to the calling session, while --service creates a persistent transient service with full systemd lifecycle management. The IOWeight property maps to the CFQ/BFQ I/O scheduler weight, providing proportional I/O bandwidth allocation.Programmatic Control via Python
For dynamic workload management—spinning up isolated workers at runtime, adjusting quotas based on telemetry, implementing backpressure mechanisms—Python’spathlib provides clean, idiomatic access to the cgroupfs interface.from __future__ import annotations
import os
import subprocess
from pathlib import Path
from typing import Final
# Micro-Rationale: Using pathlib.Path for type-safe filesystem operations
# over raw string concatenation. O(1) path construction, zero external deps.
CGROUP_ROOT: Final[Path] = Path("/sys/fs/cgroup")
class CgroupV2Controller:
"""Manages a single cgroups v2 hierarchy for process isolation.
Enforces CPU quota and memory hard limits on a named cgroup.
Implements context manager protocol for deterministic cleanup.
"""
def __init__(
self,
name: str,
cpu_quota_percent: int = 25,
memory_max_mib: int = 256,
) -> None:
if not 1 <= cpu_quota_percent <= 100:
raise ValueError(f"cpu_quota_percent must be in [1, 100], got {cpu_quota_percent}")
if memory_max_mib < 16:
raise ValueError(f"memory_max_mib must be >= 16 MiB, got {memory_max_mib}")
self.name = name
self._cpu_quota_percent = cpu_quota_percent
self._memory_max_bytes = memory_max_mib * 1024 * 1024
self._cgroup_path = CGROUP_ROOT / name
def _write(self, interface: str, value: str) -> None:
"""Writes a value to a cgroup interface file."""
target = self._cgroup_path / interface
try:
target.write_text(value, encoding="utf-8")
except PermissionError as exc:
raise PermissionError(
f"Insufficient privileges to write to {target}. "
"Run as root or with CAP_SYS_ADMIN."
) from exc
except OSError as exc:
raise OSError(f"Failed to write '{value}' to {target}: {exc}") from exc
def create(self) -> "CgroupV2Controller":
"""Creates the cgroup directory and configures resource limits."""
try:
self._cgroup_path.mkdir(parents=False, exist_ok=False)
except FileExistsError:
raise FileExistsError(f"Cgroup '{self.name}' already exists at {self._cgroup_path}")
self._write("cgroup.subtree_control", "+cpu +memory")
# CPU quota: $QUOTA $PERIOD in microseconds (CFS bandwidth throttling)
period_us = 100_000
quota_us = int(period_us * self._cpu_quota_percent / 100)
self._write("cpu.max", f"{quota_us} {period_us}")
# Memory hard limit — OOM killer fires at this threshold
self._write("memory.max", str(self._memory_max_bytes))
return self
def assign_pid(self, pid: int) -> None:
"""Moves a process into this cgroup by writing to cgroup.procs."""
try:
os.kill(pid, 0)
except ProcessLookupError:
raise ProcessLookupError(f"No process with PID {pid} found.")
self._write("cgroup.procs", str(pid))
def assign_current_process(self) -> None:
"""Moves the calling process into this cgroup."""
self.assign_pid(os.getpid())
def destroy(self) -> None:
"""Removes the cgroup directory. All processes must be migrated first."""
procs = (self._cgroup_path / "cgroup.procs").read_text().strip()
if procs:
raise OSError(
f"Cannot destroy cgroup '{self.name}': "
f"PIDs still assigned: {procs.splitlines()}"
)
self._cgroup_path.rmdir()
def __enter__(self) -> "CgroupV2Controller":
return self.create()
def __exit__(self, *_: object) -> None:
try:
self.destroy()
except OSError:
pass # Best-effort cleanup; log in production
# --- Usage ---
if __name__ == "__main__":
worker_proc = subprocess.Popen(["/usr/bin/python3", "/opt/workers/cpu_intensive_task.py"])
with CgroupV2Controller(
name="devmindset-worker",
cpu_quota_percent=20,
memory_max_mib=256,
) as cgroup:
cgroup.assign_pid(worker_proc.pid)
worker_proc.wait()Overhead Comparison: Docker vs. Direct cgroups v2
| Dimension | Docker (runc) | Direct cgroups v2 |
|---|---|---|
| Runtime daemon | containerd + dockerd | None |
| Process start latency | ~80–150ms (OCI init) | < 1ms (mkdir + write) |
| Filesystem isolation | OverlayFS mount required | Not applicable |
| Network namespace | Virtual NIC + iptables rules | Not applicable |
| Memory overhead | ~15–30 MiB per container | Zero |
| Kernel interface | Indirect (runc → seccomp → cgroup) | Direct |
| Appropriate use case | Full application isolation, portability | Single-process resource capping |
Conclusion: Choosing the Right Isolation Primitive
cgroups v2 is not a Docker alternative—it is the mechanism Docker is built on. Reaching for it directly means operating at the right abstraction level for the problem at hand. On a hardened Arch Linux system running a set of long-lived workers, background scrapers, or ML inference daemons, a 150-line Python controller and threesystemd-run flags deliver full runtime isolation without the operational surface of a container orchestration stack.The engineers who understand the kernel primitives their tools are built on will always debug faster, profile more accurately, and architect more efficiently than those who interact exclusively through abstraction layers.Since we’re descending to kernel primitives without a Docker layer, the same level of abstraction — syscalls and queues shared with the kernel — is dissected in the article on when epoll stops being enough against io_uring. What the process you’re isolating with these cgroups actually is gets covered in the piece on what fork() really does under the hood.