The Scaling Problem of I/O in Userspace
When a network application handles 10,000 connections, the “one thread per connection” model collapses against the cost wall of context switching. The classical answer is an event loop based on epoll — and for the past two decades this paradigm has powered essentially the entire modern stack: nginx, Node.js, asyncio, tokio. Everything that really handles connections fast on Linux.
Then 2019 came along with kernel 5.1, and Jens Axboe (author of the BFQ I/O scheduler) introduced io_uring — a fundamentally different asynchronous I/O model, based not on readiness notification but on completion notification, with two shared queues between userspace and kernel.
This article dissects epoll vs io_uring down to concrete syscalls, shows when the completion-based model actually wins the benchmark, and when it’s over-engineering for a workload epoll would handle on a single core with 30% headroom.
epoll — The Readiness-Based Model
Introduced in kernel 2.5.45 as an answer to the limitations of select() and poll(), epoll is a registry of file descriptors for which the kernel notifies userspace when they become ready for an operation. Three syscalls define the interface:
epoll_create1()— creates an epoll instance and returns its fdepoll_ctl()— adds/removes/modifies watched fdsepoll_wait()— blocks (or times out) until any fd becomes ready
The Critical Catch: epoll Notifies but Does Not Execute
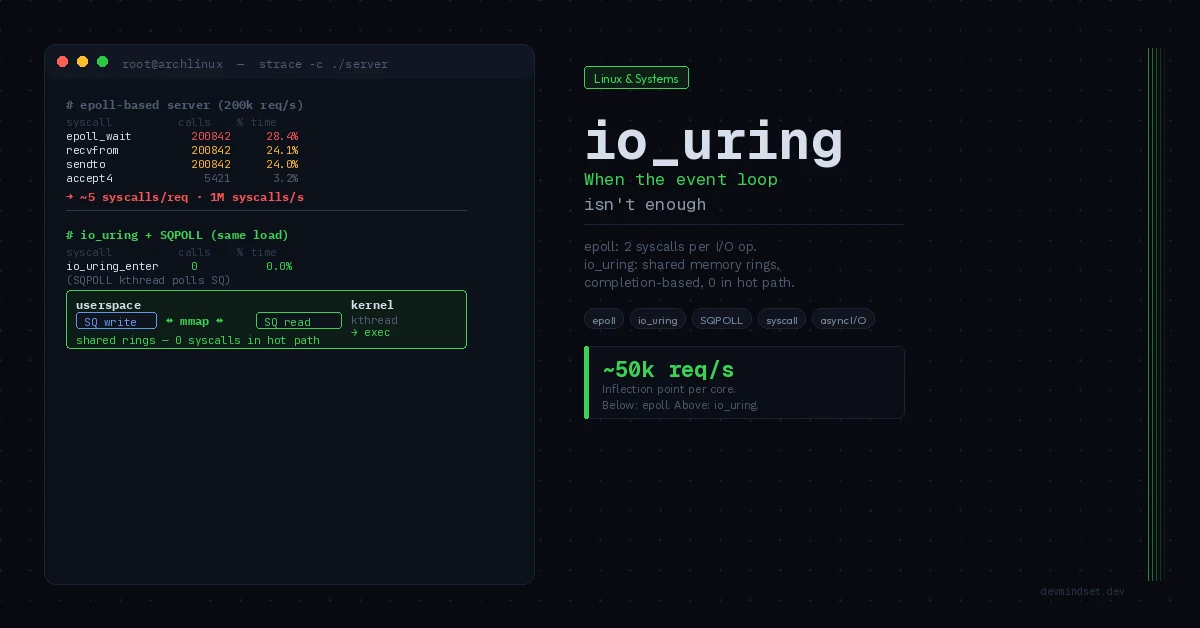
The core of the readiness-based model is that epoll_wait() says “socket X is ready to read” — but doesn’t read the data. Userspace must execute another syscall read()/recv(). Every I/O operation costs minimum two syscalls: one to learn that you can, another to actually perform.
import select
import socket
epoll = select.epoll()
server = socket.socket()
server.setblocking(False)
server.bind(("0.0.0.0", 8080))
server.listen(128)
epoll.register(server.fileno(), select.EPOLLIN | select.EPOLLET) # Edge-Triggered
connections: dict[int, socket.socket] = {}
while True:
events = epoll.poll(timeout=-1) # syscall #1: epoll_wait()
for fd, event in events:
if fd == server.fileno():
client, _ = server.accept() # syscall: accept4()
client.setblocking(False)
epoll.register(client.fileno(), select.EPOLLIN | select.EPOLLET)
connections[client.fileno()] = client
elif event & select.EPOLLIN:
sock = connections[fd]
try:
while data := sock.recv(4096): # syscall #2: recvfrom() — mandatory!
sock.send(data) # syscall #3: sendto()
except BlockingIOError:
pass # Drained, awaiting next EPOLLINFor a typical accept → read → write → close cycle we burn 4–6 syscalls per request. Each syscall is a userspace → kernel context switch costing ~100–500 ns on modern CPUs (more on machines with Spectre/Meltdown mitigations enabled). At 200k req/s × 5 syscalls = one million syscalls per second — and this is where friction begins.
Edge-Triggered vs Level-Triggered
The distinction that catches juniors in interviews. Level-Triggered (LT) — the default — notifies every time the fd is ready. Edge-Triggered (ET) notifies only once, when a state transition occurs (from not-ready to ready). ET enforces discipline: in response to a notification you must drain everything from the buffer, because there will be no second warning. This requires O_NONBLOCK + a recv() loop until EAGAIN. ET has lower overhead (fewer spurious wakeups), but a buggy implementation leads to permanent connection stall.
io_uring — The Completion-Based Model
io_uring doesn’t ask the kernel “may I?”. io_uring tells the kernel “do X, ping me when done”. The mechanics rest on two shared ring buffers in memory, mmap()-ed between userspace and kernel space:
- Submission Queue (SQ) — userspace writes operations (SQE — Submission Queue Entry)
- Completion Queue (CQ) — kernel writes results (CQE — Completion Queue Entry)
Synchronization happens through memory barriers (atomic ops on head/tail pointers), not through syscalls. Three syscalls form the entire interface: io_uring_setup(), io_uring_enter(), io_uring_register(). In SQPOLL mode io_uring_enter() becomes optional.
Anatomy of a Submitted Operation
#include <liburing.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define QUEUE_DEPTH 256
#define BUF_SIZE 4096
int main(void) {
struct io_uring ring;
if (io_uring_queue_init(QUEUE_DEPTH, &ring, 0) < 0) {
perror("io_uring_queue_init");
exit(EXIT_FAILURE);
}
int fd = open("/data/large_file.bin", O_RDONLY);
if (fd < 0) { perror("open"); exit(EXIT_FAILURE); }
char *buf = aligned_alloc(4096, BUF_SIZE);
/* Grab an SQE from the submission queue */
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
if (!sqe) { fprintf(stderr, "SQ fulln"); exit(EXIT_FAILURE); }
/* Prepare the operation — zero syscalls at this stage */
io_uring_prep_read(sqe, fd, buf, BUF_SIZE, 0);
sqe->user_data = (uint64_t)buf; /* correlation tag */
/* Submit — the only potential syscall (skipped in SQPOLL) */
io_uring_submit(&ring);
/* Wait for completion */
struct io_uring_cqe *cqe;
if (io_uring_wait_cqe(&ring, &cqe) < 0) {
perror("io_uring_wait_cqe");
exit(EXIT_FAILURE);
}
if (cqe->res < 0) {
fprintf(stderr, "Read failed: %sn", strerror(-cqe->res));
} else {
printf("Read %d bytesn", cqe->res);
}
io_uring_cqe_seen(&ring, cqe); /* release the CQ slot */
io_uring_queue_exit(&ring);
free(buf);
close(fd);
return 0;
}Key insight: read() never appears as a separate syscall. The operation is requested via a write to the SQ, the kernel executes it and reports the outcome to the CQ. A single io_uring_enter() syscall can submit arbitrarily many operations at once — batching is free.
SQPOLL — Eliminating the Syscall from the Hot Path
The IORING_SETUP_SQPOLL flag spawns a dedicated kernel thread (kthread) that continuously polls the submission queue. Userspace writes an SQE — the kthread spots it, executes the operation, writes a CQE. Zero syscalls in the hot path.
The cost: the kthread consumes a CPU core (it idles after a period configurable via sq_thread_idle) and — since kernel 5.11 — requires CAP_SYS_NICE. Previously it was CAP_SYS_ADMIN, which practically prevented SQPOLL use from non-root processes. For applications absolutely latency-critical, this was a breakthrough change.
What You Actually Save at the Syscall Level
| Hot-path operation | epoll (ET) | io_uring | io_uring + SQPOLL |
|---|---|---|---|
| Accept connection | 2 (epoll_wait + accept4) | 1 (io_uring_enter) | 0 |
| Read request | 2 (epoll_wait + recv) | 1 (io_uring_enter) | 0 |
| Write response | 2 (epoll_wait + send) | 1 (io_uring_enter) | 0 |
| Batched submit (N ops) | N × 2 syscalls | 1 syscall | 0 |
| Multi-shot accept | None (each accept individual) | 1 SQE handles many | 0 |
Multi-shot mode (since kernel 5.13) is an extra optimization: a single SQE with the IOSQE_BUFFER_SELECT flag accepts all incoming connections until manually cancelled. For servers accepting thousands of short connections this is another order of magnitude.
The Actual Numbers — Is It Worth It?
Benchmarks published by Axboe and independent tests (Cloudflare, ScyllaDB, axboe/fio) consistently show a similar pattern:
- Below 30k req/s per core — the difference falls within measurement noise. Cache effects and application code quality dominate over syscall overhead.
- At 50–100k req/s per core — io_uring starts showing a ~15–25% advantage in CPU utilization at equal throughput.
- Above 200k req/s per core — io_uring + SQPOLL achieves a 2–3× lead. Here epoll becomes the fundamental bottleneck.
- For disk I/O (random reads on NVMe) — io_uring wins even at low volumes because it also eliminates the overhead of blocking
read().
The inflection point sits around 50k req/s per core. If your service does 5k RPS across the entire cluster — io_uring is over-engineering. If you’re building a database engine, message broker, edge proxy, or file server — io_uring is the correct answer.
Compatibility and Security Concerns
io_uring is Linux-only and requires at least kernel 5.1 (5.6+ for production stability, 5.11+ for sane SQPOLL). This rules out:
- RHEL 7 (kernel 3.10) and RHEL 8 (kernel 4.18) — io_uring unavailable or archaic
- Cross-platform code — kqueue on BSD, IOCP on Windows demand their own paths
- Certain container environments — Google Kubernetes Engine blocks io_uring at the seccomp level by default, citing historical CVEs (CVE-2022-1786, CVE-2023-32233, and others)
Google has publicly disabled io_uring in production kernels for ChromeOS and Android. The rationale: io_uring’s attack surface is significantly wider than classical syscalls, and the complexity of the kernel code handling ring buffers has led to multiple privilege escalation vulnerabilities. For applications in containers on third-party infrastructure, verify whether the seccomp profile even permits io_uring_setup().
Stack Maturity — What to Use in Production
| Ecosystem | Library | Status |
|---|---|---|
| C / C++ | liburing (official, Axboe) | Production standard |
| Rust | tokio-uring, glommio | Stable; glommio for thread-per-core |
| Go | None native (Go has its own netpoll) | CGO via liburing — antipattern |
| Python | No mature support | Experimental bindings, asyncio still on epoll |
| Node.js | None | libuv stays on epoll |
| Erlang / Elixir | OTP 26+ — experimental support | Pre-production |
If you work in Go or Node — forget about io_uring entirely. These runtimes are on epoll and nothing will change that. For Python — if a service demands performance that needs io_uring, the language was the wrong architectural choice from the start.
Decision Matrix — What to Pick
| Scenario | Choice |
|---|---|
| HTTP API, < 50k RPS per node | epoll (nginx, uvloop, tokio) |
| Database engine, hot-path I/O | io_uring (ScyllaDB, MariaDB, TiKV) |
| Storage I/O — random NVMe reads | io_uring (wins even at low throughput) |
| Edge proxy > 100k connections | io_uring + SQPOLL |
| Cross-platform code (Linux + BSD + Windows) | epoll + abstraction layer |
| Containerized app with seccomp | epoll (verify seccomp profile) |
| Old kernel (RHEL 7/8, Debian 10) | epoll (no choice) |
| Go / Node.js / Python (asyncio) runtime | epoll (runtime decides for you) |
| MVP, prototype, internal tool | epoll, no debate |
Conclusion: Measurement > Ideology
io_uring is not a silver bullet. It is an excellently designed interface for a specific class of problems — workloads where syscall overhead is a measurable operational cost. For 90% of web applications, microservices, and APIs, epoll remains the optimal answer: mature, well-understood, available everywhere, compatible with every runtime.
An engineer who measures first the CPU profile under production load will see whether syscall overhead even appears in the top 10. An engineer who writes liburing code immediately because they read about it on Hacker News will likely spend a week debugging multi-shot accepts for a service serving 800 req/s that nobody will ever scale to 80k.
Premature optimization is the root of all evil — Knuth knew what he was talking about. Profile before optimizing isn’t a slogan, it’s engineering discipline.
If this level — concrete syscalls and what happens between userspace and the kernel — is your territory, a similar under-the-hood section runs through the article on what fork() in Linux really does. The performance-without-abstraction thread continues in the piece on cgroups v2 as a native runtime isolation primitive without Docker.