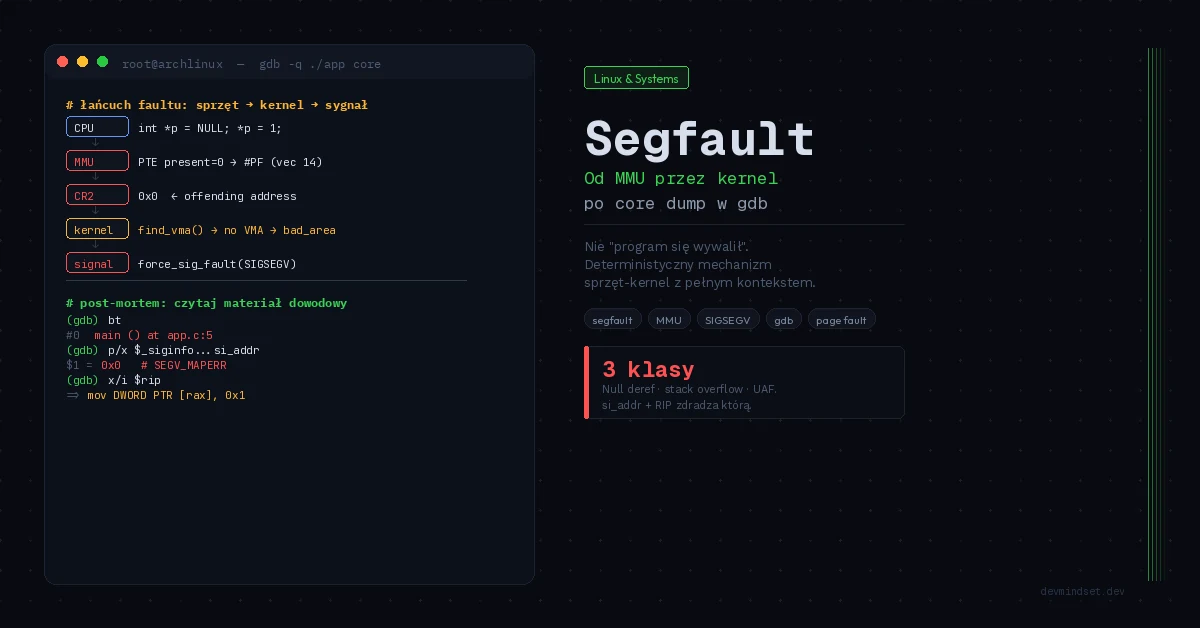
Co dokładnie dzieje się, gdy proces dotyka złego adresu
Segfault (segmentation fault) to nie „program się wywalił”. To precyzyjny, deterministyczny mechanizm ochrony pamięci, w którym MMU (Memory Management Unit) wykrywa dostęp do strony pamięci niezgodny z jej uprawnieniami, generuje wyjątek sprzętowy, kernel obsługuje go w page fault handler i — gdy nie da się go obsłużyć legalnie — wysyła sygnał SIGSEGV do procesu winowajcy.
Większość deweloperów na widok Segmentation fault (core dumped) wzrusza ramionami i dodaje printf. Inżynier rozumiejący segfault czyta core dump w gdb, lokalizuje dokładną instrukcję, identyfikuje czy to null deref, stack overflow, czy use-after-free — i naprawia przyczynę, nie objaw.
Ten artykuł rozkłada anatomię segfaulta od poziomu sprzętu (MMU, page table) przez kernel (do_page_fault, dostarczenie sygnału) po praktyczną analizę post-mortem w gdb. Bez tej wiedzy debugging błędów pamięci to zgadywanie.
Warstwa sprzętowa: MMU i translacja adresów
Każdy adres, którego dotyka twój program, to adres wirtualny. Procesor nigdy nie adresuje pamięci fizycznej bezpośrednio — między instrukcją a RAM stoi MMU, która tłumaczy adres wirtualny na fizyczny przez wielopoziomową strukturę page table.
Na x86-64 translacja używa czteropoziomowej hierarchii (PML4 → PDPT → PD → PT), gdzie każdy wpis (PTE — Page Table Entry) zawiera nie tylko adres fizyczny ramki, ale też bity uprawnień:
- Present (P) — czy strona jest w pamięci fizycznej
- Read/Write (R/W) — czy zapis jest dozwolony
- User/Supervisor (U/S) — czy userspace może dotknąć tej strony
- Execute-Disable (NX) — czy strona zawiera kod wykonywalny
Gdy instrukcja CPU próbuje dostępu naruszającego te bity — adres nie jest zmapowany (P=0), zapis do read-only (R/W=0), wykonanie strony z NX=1 — MMU generuje page fault: wyjątek sprzętowy #PF (vector 14), który przekazuje sterowanie do kernela wraz z kodem błędu i adresem winowajcy w rejestrze CR2.
Kluczowe rozróżnienie: page fault ≠ segfault
To rozróżnienie kompromituje większość kandydatów na rozmowach. Nie każdy page fault to segfault. Page fault to normalny, częsty mechanizm — kernel obsługuje miliony page faultów na sekundę bez żadnego problemu:
| Typ page fault | Co się dzieje | Czy segfault? |
|---|---|---|
| Minor fault | Strona w pamięci, brak mapowania w PT (np. współdzielona biblioteka) | ❌ Kernel mapuje, wznawia |
| Major fault | Strona wyswapowana na dysk — trzeba wczytać | ❌ Kernel ładuje z dysku |
| Demand paging | Pierwszy dostęp do zaalokowanej, ale nietkniętej strony | ❌ Kernel alokuje fizyczną ramkę |
| Copy-on-Write | Zapis do strony współdzielonej po fork() | ❌ Kernel kopiuje stronę |
| Invalid access | Adres poza legalnym vma procesu | ✅ SIGSEGV |
Dopiero gdy kernel ustali, że adresu nie da się zalegalizować — nie należy do żadnego Virtual Memory Area (VMA) procesu lub narusza uprawnienia VMA — eskaluje do SIGSEGV.
Warstwa kernela: ścieżka od #PF do SIGSEGV
Na Linuksie x86-64 obsługa zaczyna się w do_page_fault() (dziś handle_page_fault() w arch/x86/mm/fault.c). Uproszczona ścieżka decyzyjna:
/* Pseudokod ścieżki page fault handlera w kernelu */
void handle_page_fault(struct pt_regs *regs, unsigned long error_code) {
unsigned long address = read_cr2(); /* adres winowajcy */
struct vm_area_struct *vma;
/* Znajdź VMA zawierający ten adres */
vma = find_vma(current->mm, address);
if (!vma) {
/* Adres poza jakimkolwiek legalnym mapowaniem */
goto bad_area; /* → SIGSEGV */
}
if (address < vma->vm_start) {
/* Może to legalny wzrost stosu? */
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area; /* → SIGSEGV (np. stack overflow) */
expand_stack(vma, address);
}
/* Sprawdź uprawnienia: zapis do read-only? wykonanie NX? */
if ((error_code & PF_WRITE) && !(vma->vm_flags & VM_WRITE))
goto bad_area; /* → SIGSEGV (zapis do .rodata) */
/* Legalny fault — zmapuj stronę, wznów wykonanie */
handle_mm_fault(vma, address, flags);
return;
bad_area:
/* Dostarcz SIGSEGV do procesu */
force_sig_fault(SIGSEGV, si_code, (void __user *)address);
}Sygnał SIGSEGV niesie ze sobą strukturę siginfo_t z polem si_code, które rozróżnia dlaczego nastąpił segfault:
SEGV_MAPERR— adres w ogóle nie jest zmapowany (klasyczny null deref, dziki wskaźnik)SEGV_ACCERR— adres zmapowany, ale brak uprawnień (zapis do read-only, wykonanie NX)SEGV_BNDERR— naruszenie granicy (Intel MPX)SEGV_PKUERR— naruszenie protection key (PKU)
Taksonomia: trzy klasy segfaultów
Praktycznie wszystkie segfaulty sprowadzają się do trzech kategorii o fundamentalnie różnych przyczynach źródłowych.
1. Null pointer dereference
Adres 0x0 (i niska strona poniżej mmap_min_addr, domyślnie 64 KB) jest celowo niezmapowany przez kernel. To projektowa decyzja: dereferencja NULL ma natychmiast crashować, nie cicho czytać śmieci.
#include <stdio.h>
int main(void) {
int *ptr = NULL;
return *ptr; /* SIGSEGV, si_code = SEGV_MAPERR, CR2 = 0x0 */
}$ gcc -g segfault_null.c -o segfault_null
$ ./segfault_null
Segmentation fault (core dumped)
$ gdb -q ./segfault_null core
(gdb) bt
#0 0x0000555555555129 in main () at segfault_null.c:5
(gdb) print ptr
$1 = (int *) 0x0
(gdb) p/x $_siginfo._sifields._sigfault.si_addr
$2 = 0x0 # CR2 — dostęp do adresu zerowego2. Stack overflow
Nieskończona (lub zbyt głęboka) rekurencja rozrasta stos poza jego limit (RLIMIT_STACK, domyślnie 8 MB). Gdy stos próbuje wejść na stronę guard page tuż poniżej dolnej granicy VMA — kernel widzi dostęp poza legalnym obszarem i nie może go obsłużyć jako wzrostu stosu.
#include <stdio.h>
/* Rekurencja bez warunku stopu — wykładniczy wzrost stosu */
long recurse(long depth) {
char frame_buffer[4096]; /* 4 KB per ramka — szybciej wyczerpie stos */
frame_buffer[0] = (char)depth;
return recurse(depth + 1) + frame_buffer[0];
}
int main(void) {
return (int)recurse(0); /* SIGSEGV po ~2000 ramek */
}$ gdb -q ./stack_overflow core
(gdb) bt
#0 recurse (depth=2046) at stack_overflow.c:6
#1 recurse (depth=2045) at stack_overflow.c:7
#2 recurse (depth=2044) at stack_overflow.c:7
... (tysiące identycznych ramek — sygnatura stack overflow)
(gdb) p $sp
$1 = (void *) 0x7ffffffde000 # wskaźnik stosu na granicy guard page
(gdb) info proc mappings
# Adres $sp pokrywa się z dolną granicą [stack] VMASygnatura diagnostyczna: tysiące identycznych ramek w backtrace + $sp dokładnie na dolnej granicy mapowania [stack].
3. Use-after-free / heap corruption
Najpodstępniejsza klasa, bo nie zawsze crashuje deterministycznie. Dostęp do zwolnionej pamięci może działać poprawnie dopóki allocator nie odda strony do kernela (przez munmap) — wtedy adres staje się niezmapowany i dopiero wtedy następuje segfault, daleko od miejsca błędu.
#include <stdlib.h>
#include <string.h>
typedef struct {
char name[64];
void (*callback)(void); /* wskaźnik na funkcję — wektor ataku */
} Session;
int main(void) {
Session *s = malloc(sizeof(Session));
strcpy(s->name, "session-1");
free(s); /* pamięć zwolniona */
/* Use-after-free: callback wskazuje na śmieci po realokacji areny */
s->callback(); /* SIGSEGV — wykonanie spod losowego adresu */
return 0;
}Tej klasy nie debuguje się gołym gdb — potrzeba instrumentacji:
# AddressSanitizer — wykrywa use-after-free w momencie dostępu, nie crasha
$ gcc -g -fsanitize=address use_after_free.c -o uaf
$ ./uaf
==12847==ERROR: AddressSanitizer: heap-use-after-free on address 0x...
#0 0x... in main use_after_free.c:16
freed by thread T0 here:
#1 0x... in free
#2 0x... in main use_after_free.c:13 # dokładny free()
previously allocated by thread T0 here:
#3 0x... in malloc
#4 0x... in main use_after_free.c:11 # dokładny malloc()ASan podaje trzy stack trace’y: gdzie nastąpił błędny dostęp, gdzie pamięć została zwolniona, gdzie była zaalokowana. To zamienia godziny zgadywania w trzy sekundy czytania.
Praktyka: konfiguracja core dumps
Zanim cokolwiek zdebugujesz post-mortem, system musi faktycznie zapisać core dump. Domyślnie na wielu dystrybucjach jest to wyłączone (ulimit -c 0):
# Włącz nieograniczone core dumps dla bieżącej sesji
$ ulimit -c unlimited
# Gdzie systemd zapisuje core dumps (większość nowoczesnych dystrybucji)
$ cat /proc/sys/kernel/core_pattern
|/usr/lib/systemd/systemd-coredump %P %u %g %s %t %c %h
# Lista przechwyconych core dumps
$ coredumpctl list
# Otwórz najnowszy crash bezpośrednio w gdb
$ coredumpctl gdb
# Wzorzec pliku zamiast systemd-coredump (dla kontenerów/CI)
$ echo "/tmp/core.%e.%p" | sudo tee /proc/sys/kernel/core_patternMetodyka czytania backtrace
Otwarcie core dumpa to dopiero początek. Systematyczna analiza:
| Komenda gdb | Co ujawnia |
|---|---|
bt full | Backtrace z lokalnymi zmiennymi każdej ramki |
frame N | Przeskok do konkretnej ramki stosu |
info registers | Stan rejestrów w momencie crasha (RIP = błędna instrukcja) |
x/i $rip | Disasembluje instrukcję, która spowodowała segfault |
p/x $_siginfo | si_code i si_addr — dlaczego i pod jakim adresem |
info proc mappings | Mapa VMA — czy adres jest w stosie, heapie, czy nigdzie |
p variable | Wartość wskaźnika — najczęściej 0x0 lub oczywisty śmieć |
Złota reguła: zacznij od x/i $rip i p/x $_siginfo._sifields._sigfault.si_addr. Instrukcja + adres docelowy w 80% przypadków natychmiast zdradzają klasę błędu.
Narzędzia: kiedy gdb nie wystarcza
| Narzędzie | Wykrywa | Narzut |
|---|---|---|
| gdb + core | Post-mortem: gdzie crashło | Zero (po fakcie) |
| AddressSanitizer | UAF, heap/stack overflow, use-after-return | ~2× CPU, ~3× RAM |
| Valgrind (memcheck) | UAF, leaks, uninitialized reads | ~20–50× CPU |
| MemorySanitizer | Odczyt niezainicjalizowanej pamięci | ~3× CPU |
| Valgrind + vgdb | UAF z interaktywnym gdb w momencie błędu | ~20× CPU |
Reguła praktyczna: ASan w CI i development (szybki, wykrywa większość), Valgrind do trudnych przypadków (wolny, ale głębszy), gdb + core do produkcji (jedyne co masz po fakcie).
Podsumowanie: segfault jako sygnał diagnostyczny
Segfault to nie awaria losowa — to deterministyczny mechanizm sprzętowo-kernelowy, który niesie precyzyjną informację: dokładny adres (CR2/si_addr), instrukcję (RIP), powód (si_code) i pełen kontekst wykonania (core dump). Inżynier, który traktuje tę informację jak materiał dowodowy — a nie jak komunikat do zignorowania — debuguje błędy pamięci w minuty zamiast w godziny.
Mechanika jest zawsze ta sama: MMU wykrywa naruszenie → #PF → kernel próbuje zalegalizować przez VMA → niepowodzenie → SIGSEGV z pełnym kontekstem. Zrozumienie tego łańcucha zamienia „program się wywalił” w „null deref w ramce 3, linia 142, wskaźnik niezainicjalizowany po wczesnym return„.
Pamięć w C/C++ nie wybacza. Ale system operacyjny daje ci dokładnie tyle informacji, ile potrzeba — pod warunkiem, że wiesz jak ją czytać.
Mechanika stron pamięci i copy-on-write, którą rozkładamy tu na czynniki pierwsze, wygląda inaczej z perspektywy tworzenia procesu — pokazuje to tekst o tym, co naprawdę robi fork() w Linuksie pod spodem. A jeśli zamiast samego zrozumienia segfaulta interesuje Cię metodyczne dochodzenie do przyczyny każdej awarii, opisałem to w materiale o debugowaniu przez dedukcję zamiast zgadywania.