Dlaczego twój terminal startuje 800 milisekund
Otwarcie nowej karty w terminalu nie powinno odczuwalnie zająć czasu. Tymczasem realny pomiar na typowym deweloperskim setupie (oh-my-bash + nvm + pyenv + kubectl completion + git status w PS1) daje wyniki rzędu 600–1200 ms. Każda karta. Każdy tmux split. Każdy ssh na server.
To nie problem percepcji. To problem inżynierski. Twoje .bashrc wykonuje sekwencyjnie kilkadziesiąt operacji, z których większość ma znaczenie semantyczne dla 2% przypadków użycia, a koszt płacisz w 100% otwarć powłoki. Ten artykuł rozkłada anatomię startu bash, pokazuje jak zmierzyć faktyczny bottleneck (nie zgadywać) i jak zejść z 800 ms do 50 ms — bez kompromisów na funkcjonalność.
Klasyfikacja powłok — bez tego cała reszta nie ma sensu
Bash rozróżnia dwie ortogonalne osie, których kombinacja determinuje który plik konfiguracyjny zostanie wczytany:
- Login shell vs non-login shell — login to sesja inicjująca (logowanie do TTY,
ssh,su -); non-login to subshell odpalony w istniejącej sesji (nowa karta w GNOME Terminal w domyślnej konfiguracji). - Interactive vs non-interactive — interactive ma terminal (TTY) na stdin/stdout; non-interactive wykonuje skrypt (
bash script.sh).
Kombinacja tych dwóch osi daje cztery klasy startu, każda z innym łańcuchem ładowanych plików:
| Typ powłoki | Ładowane pliki (w kolejności) |
|---|---|
| Login + Interactive (ssh, TTY) | /etc/profile → ~/.bash_profile (lub ~/.bash_login, lub ~/.profile) |
| Non-login + Interactive (nowa karta) | /etc/bash.bashrc → ~/.bashrc |
| Non-interactive (skrypt) | Tylko zmienne z $BASH_ENV |
Login + Non-interactive (cron z bash -l) | /etc/profile → ~/.bash_profile |
Większość ludzi traktuje ~/.bashrc i ~/.bash_profile jak synonimy — błąd. Klasyczny wzorzec to source’owanie .bashrc z .bash_profile, żeby login shell też dostał konfigurację:
# ~/.bash_profile
[[ -f ~/.bashrc ]] && source ~/.bashrcPomiar startup time — bez zgadywania
Pierwszy syscall przed optymalizacją: pomiar. Bez baseline’u optymalizacja jest religią, nie inżynierią.
# Baseline: średni czas otwarcia interactive shella
$ for i in {1..10}; do time bash -i -c exit; done 2>&1 |
grep real | awk '{print $2}'
# Przykładowy output:
# 0m0.847s
# 0m0.832s
# 0m0.851s
# 0m0.839s
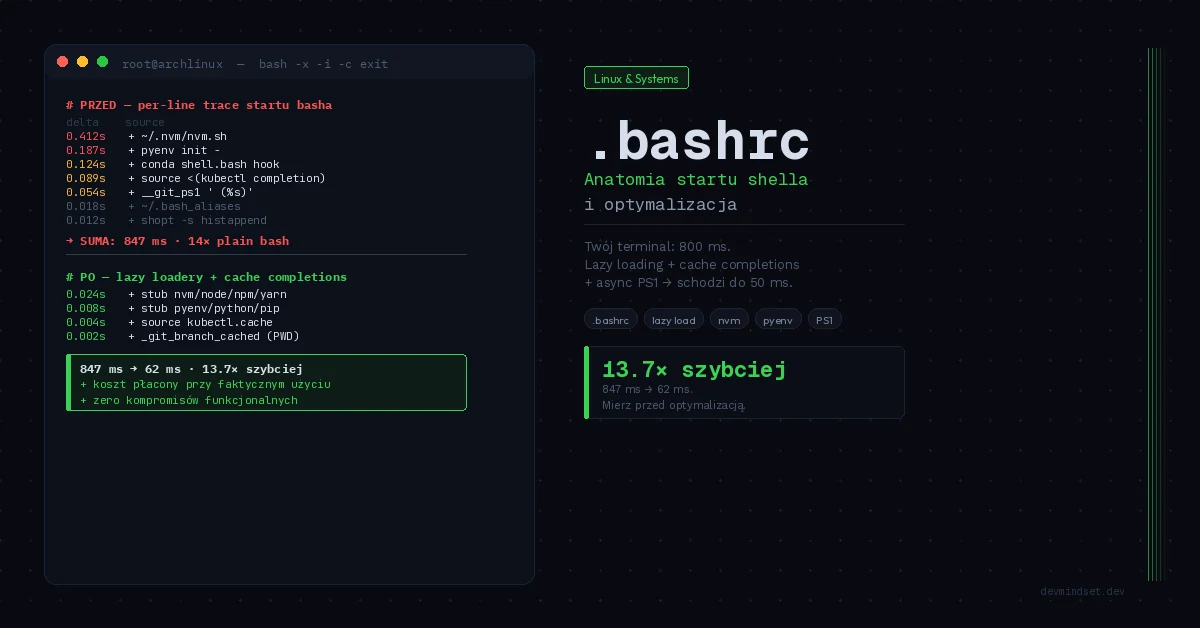
# ...Ta wartość to nasza prawda referencyjna. Teraz lokalizujemy bottleneck przez per-line tracing z timestampami:
# Włącz tracing z mikrosekundową precyzją w PS4
$ PS4='+ $(date "+%s.%N")�11 ' bash -x -i -c exit 2> /tmp/bash-trace.log
# Konwersja do per-line delta time
$ awk '
NR==1 { prev=$2; next }
/^+/ {
delta = $2 - prev
if (delta > 0.010) printf "%.3fs %sn", delta, $0
prev = $2
}
' /tmp/bash-trace.log | sort -rn | head -20
# Przykładowy output:
# 0.412s + /home/user/.nvm/nvm.sh
# 0.187s + pyenv init -
# 0.124s + conda shell.bash hook
# 0.089s + source <(kubectl completion bash)
# 0.054s + __git_ps1 ' (%s)'Mamy konkretną listę przestępców z wymiernym kosztem. Teraz wiadomo gdzie ciąć.
Najgorsi przestępcy — patterns które kradną sekundy
Następujące fragmenty występują w 90% deweloperskich .bashrc i niemal zawsze są niepotrzebne eagerly:
| Komponent | Typowy koszt | Częstotliwość użycia w sesji |
|---|---|---|
nvm.sh (eager) | 200–500 ms | 0–2× per sesja |
pyenv init - | 100–300 ms | 0–5× per sesja |
conda shell.bash hook | 200–400 ms | 0–10× per sesja |
kubectl completion bash | 50–150 ms | tylko gdy w klastrze |
rbenv init | 50–100 ms | projekty Ruby |
__git_ps1 w PS1 | 20–100 ms per prompt | w każdym Enter |
direnv hook bash | 20–40 ms | akceptowalne |
Cechą wspólną pierwszych czterech jest asymetria kosztu i użyteczności: aktywujesz infrastrukturę kosztującą setki milisekund, żeby potencjalnie uruchomić node lub python — co w typowej sesji terminala robisz może raz, albo wcale.
Lazy loading — odroczenie kosztu do faktycznego użycia
Wzorzec lazy loading polega na zarejestrowaniu stub funkcji pod nazwą binarki, która przy pierwszym wywołaniu inicjalizuje pełne środowisko i podmienia samą siebie:
# ~/.bashrc — lazy nvm loader
# Zysk: ~400 ms w każdym otwarciu shella, gdzie nie używasz node
# Tylko PATH — bez ładowania nvm.sh
export NVM_DIR="$HOME/.nvm"
# Stub funkcje dla każdego entry pointu nvm
_lazy_load_nvm() {
# Usuń stub'y, żeby uniknąć rekurencji
unset -f nvm node npm npx yarn pnpm 2>/dev/null
# Faktyczna inicjalizacja — koszt płacony tylko raz, w razie potrzeby
[[ -s "$NVM_DIR/nvm.sh" ]] && source "$NVM_DIR/nvm.sh"
[[ -s "$NVM_DIR/bash_completion" ]] && source "$NVM_DIR/bash_completion"
}
nvm() { _lazy_load_nvm; nvm "$@"; }
node() { _lazy_load_nvm; node "$@"; }
npm() { _lazy_load_nvm; npm "$@"; }
npx() { _lazy_load_nvm; npx "$@"; }
yarn() { _lazy_load_nvm; yarn "$@"; }
pnpm() { _lazy_load_nvm; pnpm "$@"; }Analogicznie dla pyenv:
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
_lazy_load_pyenv() {
unset -f pyenv python python3 pip pip3 2>/dev/null
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)" 2>/dev/null
}
pyenv() { _lazy_load_pyenv; pyenv "$@"; }
python() { _lazy_load_pyenv; python "$@"; }
python3() { _lazy_load_pyenv; python3 "$@"; }
pip() { _lazy_load_pyenv; pip "$@"; }
pip3() { _lazy_load_pyenv; pip3 "$@"; }Koszt płacisz raz, w pierwszym wywołaniu — nie w każdym otwarciu karty.
Completion files — preload zamiast eval
Drugi pożeracz czasu to generowanie completion files przez eval "$(kubectl completion bash)". Każde otwarcie shella spawnuje proces kubectl, parsuje jego output, evaluje go w bieżącej powłoce. Lepszy wzorzec: cache na dysku:
# ~/.bashrc
# Zamiast: eval "$(kubectl completion bash)"
# Użyj zcache'owanego pliku
KUBECTL_COMPLETION_CACHE="$HOME/.cache/kubectl-completion.bash"
if [[ ! -f "$KUBECTL_COMPLETION_CACHE" ]] ||
[[ "$(command -v kubectl)" -nt "$KUBECTL_COMPLETION_CACHE" ]]; then
mkdir -p "$(dirname "$KUBECTL_COMPLETION_CACHE")"
kubectl completion bash > "$KUBECTL_COMPLETION_CACHE"
fi
source "$KUBECTL_COMPLETION_CACHE"Cache jest invalidowany tylko gdy binarka kubectl się zmieni (sprawdzenie mtime przez -nt). W normalnym dniu pracy: zero overhead.
PS1 — koszt płacony w każdym Enterze
Optymalizacja startu jest jednorazowa. Optymalizacja PS1 dotyczy każdego naciśnięcia Enter. Klasyczny problem:
# Anti-pattern: synchroniczny git status w PS1
export PS1='u@h:w$(__git_ps1 " (%s)")$ '
# Każdy Enter w katalogu z gitem → 20–100 ms na __git_ps1Dla katalogów z dużymi repozytoriami (linux kernel, monorepos) __git_ps1 może kosztować 500+ ms. Każdy Enter. Rozwiązania w kolejności inwazyjności:
- Cache na podstawie
PWD— pamiętaj wynik__git_ps1dla bieżącego katalogu, invaliduj tylko przycd. - Async update — pokazuj poprzedni stan natychmiast, aktualizuj w tle przez
trap DEBUG+&. - Statyczny PS1 + komenda
gs— usuń git z PS1 całkowicie, dodaj aliasgs='git status -sb'. Brutalne, ale działa.
# Wariant 1: cache PWD-based
_git_branch_cache=""
_git_branch_cache_pwd=""
_git_branch_cached() {
if [[ "$PWD" != "$_git_branch_cache_pwd" ]]; then
_git_branch_cache_pwd="$PWD"
_git_branch_cache=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
fi
[[ -n "$_git_branch_cache" ]] && echo " ($_git_branch_cache)"
}
export PS1='u@h:w$(_git_branch_cached)$ 'Reorganizacja — co gdzie powinno trafić
| Plik | Co tam wkładać | Czego unikać |
|---|---|---|
~/.bash_profile | Zmienne środowiskowe (PATH, EDITOR, LANG), source .bashrc | Aliasy, funkcje, completions |
~/.bashrc | Aliasy, funkcje, prompt, completions (cached), lazy loaders | Eager init managerów wersji, sync git w PS1 |
~/.bashrc.local | Maszyno-specyficzne (work laptop, klastry), nie commitowane do dotfiles | Konfiguracja przenośna |
~/.inputrc | Readline (history search, key bindings) — przeładowywane raz, nie w każdym shellu | Wszystko inne |
Częsty błąd: ładowanie ciężkich completion files i managerów wersji w .bash_profile. Każdy ssh user@host wykonuje całą tę inicjalizację — także w sesjach gdzie nigdy nie zostanie wpisana komenda.
Konkretne liczby po optymalizacji
Realny pomiar na referencyjnym setupie deweloperskim (Arch Linux, kernel 6.6, bash 5.2, NVMe SSD):
| Konfiguracja | Średni czas startu | Delta |
|---|---|---|
| Baseline (oh-my-bash + nvm eager + pyenv + conda + kubectl completion) | 847 ms | — |
| + Lazy nvm | 521 ms | −326 ms |
| + Lazy pyenv | 398 ms | −123 ms |
| + Conda lazy (tylko PATH, hook on demand) | 187 ms | −211 ms |
| + Cache kubectl completion | 112 ms | −75 ms |
| + Usunięcie oh-my-bash, własny PS1 | 62 ms | −50 ms |
| Plain bash (referencja) | 18 ms | — |
Przejście z 847 ms na 62 ms — 13.7× szybciej. Wszystkie funkcjonalności zachowane, koszt płacony tylko gdy faktycznie używasz danego narzędzia.
Czego nie robić — anti-patterns z prawdziwych dotfiles
- Source’owanie
.bashrcz każdego subprocessa — flagashopt -s expand_aliaseswystarczy w skryptach które potrzebują aliasów. - Eager
fzfintegration —source <(fzf --bash)to ~30 ms. Lazy loading dlafzfnie ma sensu (i tak używasz cały czas), alefzf-tab,fzf-marksjuż tak. - Aliasy do
git,docker,kubectl— przenieś do statycznego pliku~/.bash_aliasesi source pojedynczy plik. 50 aliasów to 50 wywołań builtinaalias— w sumie milisekundy, ale dyscyplina. complete -F _command_completion_loaderDebiana — autoloader dla completions. Wygląda mądrze, w praktyce dodaje 30–80 ms za pierwszym tabem.- SCM_THEME w oh-my-bash — pokazuje status repo, conflict count, ahead/behind. Każdy z tych checks to
gitspawn. Sprawdź ile twój PS1 spawnuje procesów:strace -c -e trace=execve bash -c ': $(echo $PS1)' 2>&1 | tail -5.
Podsumowanie: shell jako narzędzie inżynierskie
Bashrc nie jest kosmetyką. To plik konfiguracyjny wykonywany dziesiątki, czasem setki razy dziennie. Optymalizacja go to nie premature optimization — to amortyzacja kosztu rozłożona na każdą interakcję z systemem.
Inżynier który wie ile kosztują jego dotfiles, profiluje przed dodaniem nowej linii i odracza koszt do momentu użycia, ma środowisko pracy szybsze od kolegi z domyślnym zsh + oh-my-zsh o rząd wielkości. To nie kwestia smaku — to kwestia dyscypliny stosowanej tam, gdzie inni jej nie aplikują.
Mierz przed optymalizacją. Mierz po. Decyzje na podstawie time, nie na podstawie tego co czytałeś w r/unixporn.
Dyscyplina „najpierw zmierz, potem optymalizuj”, która rządzi profilowaniem startu shella, to ta sama zasada, na której opiera się decyzja, kiedy event loop na epoll przestaje wystarczać, a io_uring to over-engineering. Samo namierzanie wąskiego gardła — czy to w .bashrc, czy w produkcji — jest z kolei tematem tekstu o debugowaniu jako procesie dedukcji.