Why Your Terminal Takes 800 Milliseconds to Start
Opening a new terminal tab should feel instantaneous. Yet real measurements on a typical developer setup (oh-my-bash + nvm + pyenv + kubectl completion + git status in PS1) consistently land in the 600–1200 ms range. Every tab. Every tmux split. Every ssh into a server.
This isn’t a perception problem. It’s an engineering one. Your .bashrc sequentially executes dozens of operations, most of which carry semantic value for 2% of use cases — while you pay the cost in 100% of shell openings. This article dissects bash startup anatomy, shows how to measure the actual bottleneck (not guess), and how to drop from 800 ms to 50 ms with no functionality compromise.
Shell Classification — Without This, Nothing Else Makes Sense
Bash distinguishes two orthogonal axes, whose combination determines which configuration file gets loaded:
- Login vs non-login shell — login means an initiating session (TTY login,
ssh,su -); non-login is a subshell spawned inside an existing session (new tab in GNOME Terminal under default config). - Interactive vs non-interactive — interactive has a terminal (TTY) on stdin/stdout; non-interactive executes a script (
bash script.sh).
The combination produces four startup classes, each with a different loading chain:
| Shell type | Loaded files (in order) |
|---|---|
| Login + Interactive (ssh, TTY) | /etc/profile → ~/.bash_profile (or ~/.bash_login, or ~/.profile) |
| Non-login + Interactive (new tab) | /etc/bash.bashrc → ~/.bashrc |
| Non-interactive (script) | Only variables from $BASH_ENV |
Login + Non-interactive (cron with bash -l) | /etc/profile → ~/.bash_profile |
Most people treat ~/.bashrc and ~/.bash_profile as synonyms — wrong. The classical pattern is sourcing .bashrc from .bash_profile so that login shells also pick up the configuration:
# ~/.bash_profile
[[ -f ~/.bashrc ]] && source ~/.bashrcMeasuring Startup Time — No Guessing
First syscall before optimization: measurement. Without a baseline, optimization is religion, not engineering.
# Baseline: average interactive shell open time
$ for i in {1..10}; do time bash -i -c exit; done 2>&1 |
grep real | awk '{print $2}'
# Example output:
# 0m0.847s
# 0m0.832s
# 0m0.851s
# 0m0.839s
# ...This number is our reference truth. Now we locate the bottleneck via per-line tracing with timestamps:
# Enable tracing with microsecond precision via PS4
$ PS4='+ $(date "+%s.%N")�11 ' bash -x -i -c exit 2> /tmp/bash-trace.log
# Convert to per-line delta time
$ awk '
NR==1 { prev=$2; next }
/^+/ {
delta = $2 - prev
if (delta > 0.010) printf "%.3fs %sn", delta, $0
prev = $2
}
' /tmp/bash-trace.log | sort -rn | head -20
# Example output:
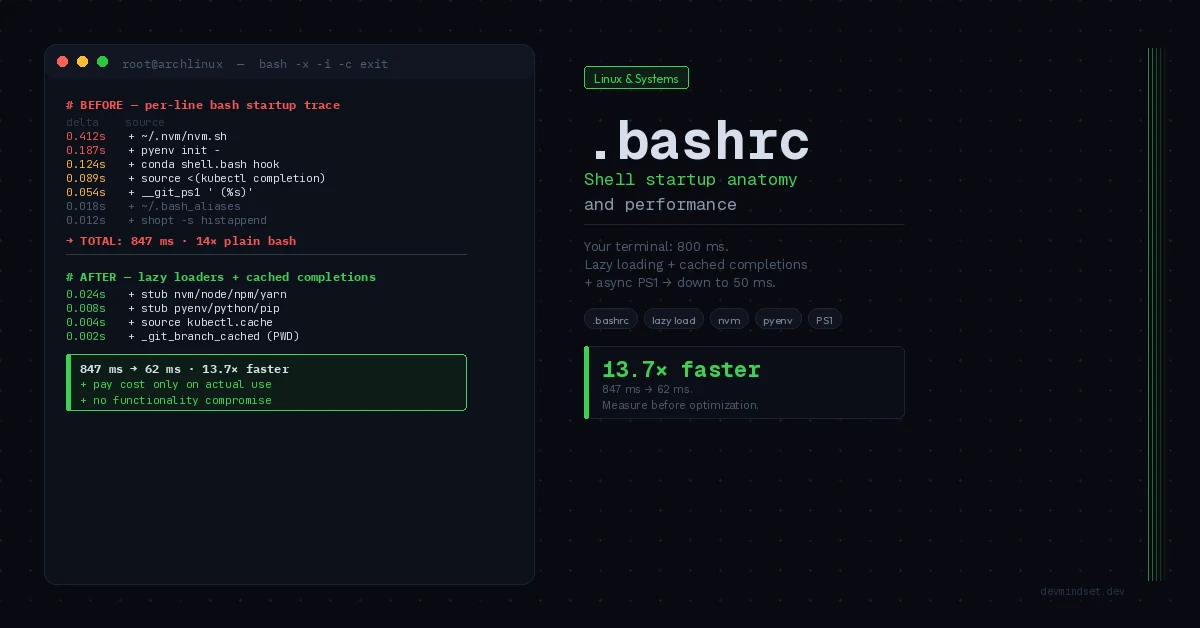
# 0.412s + /home/user/.nvm/nvm.sh
# 0.187s + pyenv init -
# 0.124s + conda shell.bash hook
# 0.089s + source <(kubectl completion bash)
# 0.054s + __git_ps1 ' (%s)'We now have a concrete list of offenders with measurable cost. Now we know where to cut.
The Worst Offenders — Patterns That Steal Seconds
The following snippets appear in 90% of developer .bashrc files and are almost never necessary eagerly:
| Component | Typical cost | Session usage frequency |
|---|---|---|
nvm.sh (eager) | 200–500 ms | 0–2× per session |
pyenv init - | 100–300 ms | 0–5× per session |
conda shell.bash hook | 200–400 ms | 0–10× per session |
kubectl completion bash | 50–150 ms | cluster-only |
rbenv init | 50–100 ms | Ruby projects |
__git_ps1 in PS1 | 20–100 ms per prompt | every Enter |
direnv hook bash | 20–40 ms | acceptable |
The shared trait of the first four is cost-to-utility asymmetry: you activate infrastructure costing hundreds of milliseconds to potentially run node or python — which in a typical terminal session you do maybe once, or not at all.
Lazy Loading — Deferring Cost to Actual Usage
The lazy loading pattern registers a stub function under the binary name, which on first invocation initializes the full environment and replaces itself:
# ~/.bashrc — lazy nvm loader
# Saves: ~400 ms on every shell open where you don't use node
# PATH only — without loading nvm.sh
export NVM_DIR="$HOME/.nvm"
# Stub functions for every nvm entry point
_lazy_load_nvm() {
# Unset stubs to avoid recursion
unset -f nvm node npm npx yarn pnpm 2>/dev/null
# Actual initialization — cost paid only once, on demand
[[ -s "$NVM_DIR/nvm.sh" ]] && source "$NVM_DIR/nvm.sh"
[[ -s "$NVM_DIR/bash_completion" ]] && source "$NVM_DIR/bash_completion"
}
nvm() { _lazy_load_nvm; nvm "$@"; }
node() { _lazy_load_nvm; node "$@"; }
npm() { _lazy_load_nvm; npm "$@"; }
npx() { _lazy_load_nvm; npx "$@"; }
yarn() { _lazy_load_nvm; yarn "$@"; }
pnpm() { _lazy_load_nvm; pnpm "$@"; }Analogous pattern for pyenv:
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
_lazy_load_pyenv() {
unset -f pyenv python python3 pip pip3 2>/dev/null
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)" 2>/dev/null
}
pyenv() { _lazy_load_pyenv; pyenv "$@"; }
python() { _lazy_load_pyenv; python "$@"; }
python3() { _lazy_load_pyenv; python3 "$@"; }
pip() { _lazy_load_pyenv; pip "$@"; }
pip3() { _lazy_load_pyenv; pip3 "$@"; }You pay the cost once, on first invocation — not on every tab open.
Completion Files — Preload Instead of Eval
The second time sink is generating completion files via eval "$(kubectl completion bash)". Every shell open spawns a kubectl process, parses its output, evaluates it in the current shell. A better pattern: cache on disk:
# ~/.bashrc
# Instead of: eval "$(kubectl completion bash)"
# Use a cached file
KUBECTL_COMPLETION_CACHE="$HOME/.cache/kubectl-completion.bash"
if [[ ! -f "$KUBECTL_COMPLETION_CACHE" ]] ||
[[ "$(command -v kubectl)" -nt "$KUBECTL_COMPLETION_CACHE" ]]; then
mkdir -p "$(dirname "$KUBECTL_COMPLETION_CACHE")"
kubectl completion bash > "$KUBECTL_COMPLETION_CACHE"
fi
source "$KUBECTL_COMPLETION_CACHE"The cache invalidates only when the kubectl binary changes (mtime check via -nt). On a normal workday: zero overhead.
PS1 — The Cost Paid on Every Enter
Startup optimization is one-time. PS1 optimization applies to every Enter keystroke. The classic problem:
# Anti-pattern: synchronous git status in PS1
export PS1='u@h:w$(__git_ps1 " (%s)")$ '
# Every Enter in a git directory → 20–100 ms on __git_ps1For directories with large repositories (linux kernel, monorepos) __git_ps1 can cost 500+ ms. Every Enter. Solutions in increasing order of invasiveness:
- PWD-based cache — memoize the
__git_ps1result for the current directory, invalidate only oncd. - Async update — show the previous state immediately, update in the background via
trap DEBUG+&. - Static PS1 +
gsalias — remove git from PS1 entirely, addgs='git status -sb'. Brutal, but effective.
# Variant 1: PWD-based cache
_git_branch_cache=""
_git_branch_cache_pwd=""
_git_branch_cached() {
if [[ "$PWD" != "$_git_branch_cache_pwd" ]]; then
_git_branch_cache_pwd="$PWD"
_git_branch_cache=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
fi
[[ -n "$_git_branch_cache" ]] && echo " ($_git_branch_cache)"
}
export PS1='u@h:w$(_git_branch_cached)$ 'Reorganization — What Belongs Where
| File | What goes there | What to avoid |
|---|---|---|
~/.bash_profile | Environment vars (PATH, EDITOR, LANG), source .bashrc | Aliases, functions, completions |
~/.bashrc | Aliases, functions, prompt, completions (cached), lazy loaders | Eager version-manager init, sync git in PS1 |
~/.bashrc.local | Machine-specific (work laptop, clusters), not committed to dotfiles | Portable configuration |
~/.inputrc | Readline (history search, key bindings) — reloaded once, not per shell | Everything else |
A frequent mistake: loading heavy completion files and version managers in .bash_profile. Every ssh user@host runs this entire initialization — including sessions where no command will ever be typed.
Concrete Numbers After Optimization
Real measurement on a reference developer setup (Arch Linux, kernel 6.6, bash 5.2, NVMe SSD):
| Configuration | Average startup time | Delta |
|---|---|---|
| Baseline (oh-my-bash + eager nvm + pyenv + conda + kubectl completion) | 847 ms | — |
| + Lazy nvm | 521 ms | −326 ms |
| + Lazy pyenv | 398 ms | −123 ms |
| + Conda lazy (PATH only, hook on demand) | 187 ms | −211 ms |
| + Cached kubectl completion | 112 ms | −75 ms |
| + Drop oh-my-bash, custom PS1 | 62 ms | −50 ms |
| Plain bash (reference) | 18 ms | — |
From 847 ms down to 62 ms — 13.7× faster. All functionality preserved, cost paid only when you actually use a given tool.
What Not to Do — Anti-patterns From Real Dotfiles
- Sourcing
.bashrcfrom every subprocess — theshopt -s expand_aliasesflag is enough in scripts that need aliases. - Eager
fzfintegration —source <(fzf --bash)is ~30 ms. Lazy loadingfzfitself makes no sense (you use it constantly), butfzf-tab,fzf-marksare different stories. - Aliases for
git,docker,kubectl— move to a static~/.bash_aliasesfile and source once. 50 aliases = 50aliasbuiltin calls — milliseconds in total, but discipline matters. - Debian’s
complete -F _command_completion_loader— autoloader for completions. Looks clever; in practice adds 30–80 ms on first tab. SCM_THEMEin oh-my-bash — shows repo status, conflict count, ahead/behind. Each check is agitspawn. Inspect your PS1 process count:strace -c -e trace=execve bash -c ': $(echo $PS1)' 2>&1 | tail -5.
Conclusion: The Shell as an Engineering Tool
Bashrc isn’t cosmetics. It’s a configuration file executed dozens, sometimes hundreds of times daily. Optimizing it isn’t premature optimization — it’s amortizing cost across every interaction with the system.
An engineer who knows what their dotfiles cost, profiles before adding a new line, and defers cost to actual usage, has a work environment an order of magnitude faster than a colleague running default zsh + oh-my-zsh. This isn’t a matter of taste — it’s a matter of discipline applied where others don’t apply it.
Measure before optimizing. Measure after. Decisions based on time, not based on what you read on r/unixporn.
The “measure first, optimize second” discipline that governs profiling shell startup is the same principle behind deciding when an epoll event loop stops being enough and when io_uring is over-engineering. Pinning down the bottleneck itself — whether in .bashrc or in production — is in turn the theme of the piece on debugging as a process of deduction.