Debugging like a developer is one of the most important skills in working with code — and one of the worst-trained ones. You have a bug in production. You look at the stack trace, open the file the trace points to at line 47, and start poking around. You change one variable, deploy, wait. Didn’t help. You change another. Wait. Maybe this time.
This isn’t debugging. It’s gambling with production code.
The problem is that most of us never learned to debug — we only learned to accidentally fix bugs. Those are two completely different things.
Trial-and-error debugging is an illusion of control
Imagine a doctor who prescribes random medications to every patient until one works. No tests, no diagnosis — just trying things. You’d call them incompetent. Yet this is exactly how most developers approach debugging.
Classic symptoms of bad debugging:
- You drop
console.logorprint()in random places throughout the code - You change several things at once, because “maybe one of them will fix it”
- You search Stack Overflow before fully understanding the error
- You restart the service “to see if it helps”
- You describe the problem as “something is broken” instead of a specific behavior
Every one of these habits has one thing in common: you’re acting without a hypothesis. Without a hypothesis you’re not debugging — you’re guessing.
How developers debug when they actually know what they’re doing — debugging like a developer
Debugging is a process of deduction, not exploration. The difference is fundamental.
Exploration means: “I don’t know what’s wrong, so I’ll poke around until I find it.”
Deduction means: “I know how the system should behave. I observe how it behaves. The gap between expectation and observation is my starting point.”
Before you touch any code, you need to answer three questions:
1. What is the exact, reproducible behavior of the system?
Not “something breaks on login.” Specifically: “A user whose email contains a + character can’t log in. The error only appears with OAuth, not password login. It reproduces on staging but not locally.”
The more precisely you describe the problem, the faster you’ll solve it. This isn’t pedantry — it’s basic debugging hygiene.
2. What is your expected behavior and how do you know?
You need a reference point. Do you have documentation? Tests? A previous commit where it worked? Without an answer to this question, you don’t even know what you’re looking for.
3. What’s your hypothesis?
One specific hypothesis before you change anything. “I suspect the URL encoder in library X doesn’t handle the + character in the email parameter.” Then you verify that hypothesis — and only that one. If it turns out to be false, you form the next one.
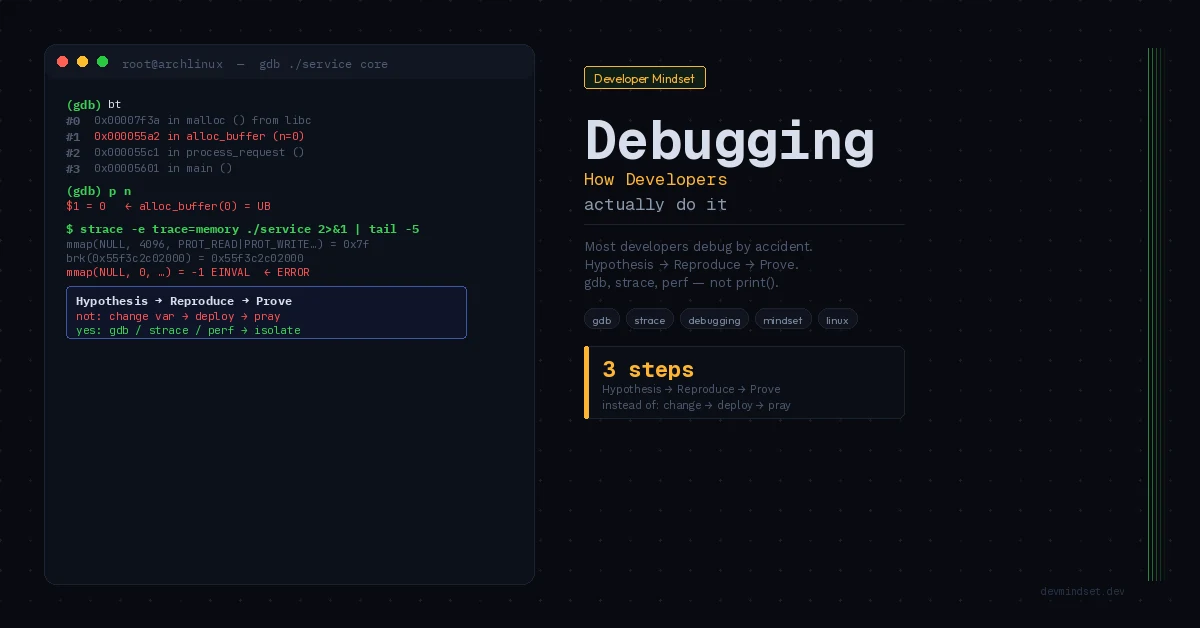
Tools that shift the perspective
Most developers use a debugger like a flashlight in a dark room — pointing it wherever. A debugger is a tool for verifying hypotheses, not for generating them.
Binary search on code
When you don’t know where the bug is, you don’t start at the top of the file. You set a breakpoint halfway through the execution path. Does the error happen before or after? You’ve eliminated half the problem in one step. Repeat. That’s O(log n) debugging instead of O(n).
Variable isolation
Every change in the environment is a potential cause. Before you start digging through code, ask: what changed since the last time it worked? New library version? Config change? Database migration? A commit from last week?
git bisect is one of the most underrated tools in the developer ecosystem — it lets you binary-search the commit history to find the exact commit that introduced the regression. Most developers don’t even know it exists.
Logs as narrative, not noise
You read logs the way a detective reads witness statements — looking for inconsistencies, not confirmation of your theory. If you only log errors, you’re blind to what happens right before the error. A good log is context: who, what, when, with what input.
The mistake that costs hours: debugging the symptom instead of the cause
The stack trace points to line 203. You go to line 203 and start looking there. That’s a mistake.
Line 203 is where the system screams — not where the crime was committed. The logical error often appears 10, 20, 50 lines earlier, at the point where data enters the system in a bad state. Line 203 just happens to be the first place that can’t handle it.
Learn to read stack traces top-down, but think about them bottom-up. Where did the data enter the system? What should it have contained? What does it actually contain? Somewhere between input and symptom lies the cause.
When you’re stuck: the rubber duck technique
You’ve been on a problem for 45 minutes and have nothing. Don’t open Stack Overflow. Instead, explain the problem out loud — literally, in words — to anyone nearby. Or to a rubber duck on your desk. Or to a text file.
This isn’t a joke. When you force yourself into a linear verbal description of the problem, your brain processes it differently than when visually scanning code. In 60% of cases the solution appears mid-explanation, before you’ve finished the sentence.
If you have no one to talk to, write. GitHub Issues, a Slack message to yourself, a notepad. Full problem description: what you see, what you expect, what you’ve already checked, what your current hypothesis is.
What this post doesn’t cover — and why
You won’t find a list of debugging tools with every keyboard shortcut here. Not because tools don’t matter — but because a bad approach with better tools just gets you to bad results faster.
Effective debugging like a developer always starts with a precise description of the problem — not with opening a file.
Effective debugging always starts with a precise description of the problem — not with opening a file.
What to do differently starting today
Next time you hit a bug, before you touch any code — write three sentences in a comment or text file:
- The exact, reproducible behavior you observe.
- The exact behavior you expect, and how you know.
- Your first hypothesis about the cause.
If you can’t write those three sentences, you’re not ready to debug. Go back to observing the system.
This is the habit that separates engineers who “somehow fix things” from those who understand what they’re fixing and why — and that’s what debugging like a developer really means.
Methodically reaching the root cause has its most concrete case in memory-fault analysis — broken down in the piece on the anatomy of a segfault, from the MMU through the kernel to a gdb core dump. The deduction skill the whole process rests on, in turn, starts with reading other people’s code faster than you wrote your own — because in both cases you build a model of the system before you touch it.